An Introduction to Layer 3 Traffic Isolation
All network engineers should be familiar with the method for virtualizing the network at Layer 2: the VLAN. VLANs are used to virtualize the bridging table of Layer 2 switches and create virtual switching topologies that overlay the physical network. Traffic traveling in one topology (ie VLAN) cannot bleed through into another topology. In this way, traffic from one group of users or devices can be kept isolated from other users or devices.
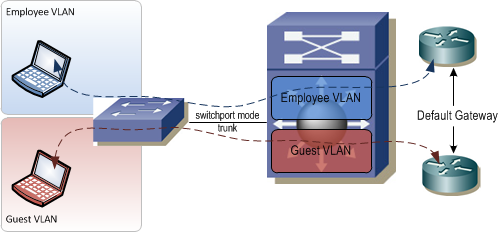
VLANs work great in a Layer 2 switched network, but what happens when you need to maintain this traffic separation across a Layer 3 boundary such as a router or firewall?
Typically, if you have two VLANs that each terminate on a router and the router has an IP address in each VLAN, the devices in those VLANs are free to talk to each other by passing traffic through the router. That traffic isolation that was gained by putting the devices in different VLANs is now lost. In fact, because some network engineers are only familiar with traffic isolation at Layer 2 and not at Layer 3, the overall network design will often be compromised to allow for VLANs to span end-to-end in the network so that traffic separation can be maintained. This of course necessitates bridging everywhere in the network which can lead to serious issues.
There is a way to maintain traffic isolation across Layer 3 devices. It's called Virtual Routing and Forwarding. Virtual Routing and Forwarding, aka VRF, allows the routing table in a Layer 3 switch or router to be virtualized. Each virtualized table contains its own unique set of forwarding entries. Traffic that enters a router will be forwarded using the routing table associated with the same VRF that the ingress interface is associated with and will be sent out an egress interface associated with the same VRF. Much like VLANs, VRFs ensure logical isolation of traffic as it crosses a common physical network infrastructure.
There are three general concepts behind VRFs:
- Access Control
- Path Isolation
- Shared Services
The next sections look at each of these in turn.
Access Control⌗
Access control refers to how end devices are identified and segmented at the network edge (aka, access layer). Users need to be segmented before they input traffic into the network so that the network knows which virtual network to associate their traffic with. Access control must take into consideration both wired and wireless network access methods.
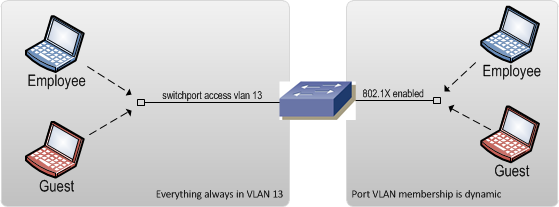
Two of the most common methods for segmenting wired end devices is by static VLAN assignment and 802.1X Network Access Control. Static VLAN assignment is where a VLAN is configured on an edge port and that VLAN does not change regardless of who or what is plugged in.
switch(config-if)# switchport mode access
switch(config-if)# switchport access vlan 101
This method is simple to implement but is costly to maintain. Every time a new device is plugged into the port the VLAN might have to be changed. If the port is located in someone's office then this might not happen very often, but if the port is in a meeting room it can be a nightmare if you have a mixture of employees and guests plugging in. Additionally, if the port is left on the employee VLAN and a guest plugs in, they are now on the employee network and can access the same network resources as employees. This is an obvious security risk. Although it's hard to maintain, static VLAN assignment is easy and inexpensive to implement and requires no additional equipment, tools, or training.
The more advanced alternative to static VLAN assignments is to employ 802.1X on all edge ports. The 802.1X standard is a method of authenticating end devices to the network. Based on the results of the authentication and the policies in place, the network can automatically assign a VLAN to a port (among other things). Presumably, devices being used by employees would successfully authenticate and be placed on the employee VLAN. Devices owned by guests would fail the authentication and be placed into the guest VLAN. Implementing 802.1X however, is rather complex. It requires additional equipment to perform the authentication and run the policy engine that determines things like VLAN assignment. The upside though is that it removes the burden of manually tweaking VLAN assignments and ensures that the end devices are always placed into the correct VLAN, eliminating the risk of guests getting on the employee VLAN.
On the wireless side, end devices can be segmented by way of separate SSIDs for different groups of users. An SSID could be created for employees, guests, and contractors each of which is bound to its own VLAN on the uplink side of the wireless controller. Mechanisms such as 802.1X can also be employed on wireless connections to bind an end device to a certain VLAN after it's associated with the wireless network.
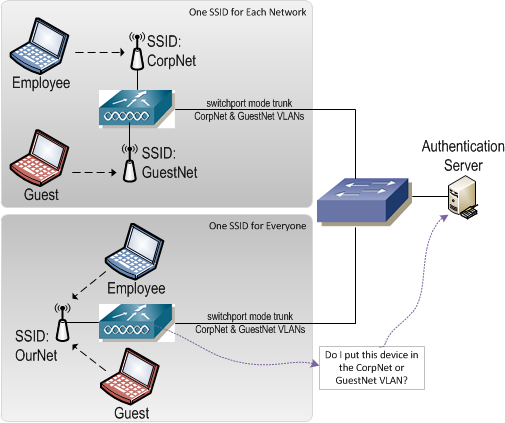
In the end, all of these solutions segregate end devices by placing them in the appropriate VLAN. VLAN assignment is the first step in segregating end device traffic. Traffic entering the network on that VLAN will eventually hit a Layer 3 device where it will be forwarded based on the routing table that is part of the VRF to which the VLAN is bound.
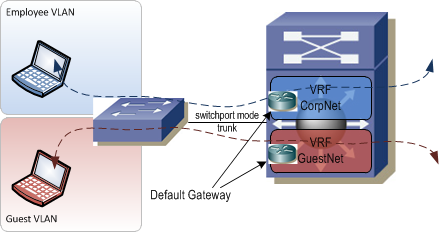
Path Isolation⌗
Path isolation refers to the method used within the core of the network to keep each VRF's traffic isolated. As stated earlier, once traffic hits a Layer 3 device, it will normally be forwarded between interfaces which may allow traffic to route between VLANs. Each of the path isolation methods below keeps traffic inside its assigned VRF as it travels between Layer 3 devices.
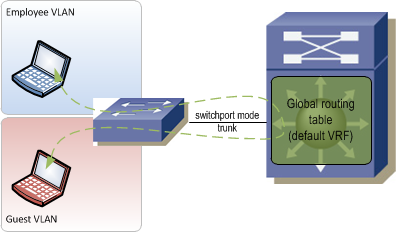
The hop-by-hop method creates switched virtual interfaces (SVIs) on top of 802.1q tags between each Layer 3 device in the network. For each pair of connected devices, there is (1) SVI created per device, per VRF. Unlike a Layer 2 network where VLAN tags are bridged end-to-end, each tag is used only on one interconnect and each device acts as a Layer 3 hop in the traffic path. When everything is fully provisioned, you end up with a path through the network that is strung together by SVIs. This can be really cumbersome to manage since for every VRF you have to configure multiple interfaces from edge to edge and manage all that extra IP addressing too. If there are multiple potential paths through the network from edge to edge, then the SVI string needs to be provisioned on the alternate paths as well. The upside is that SVIs are relatively easy to understand and are very well supported on all types of hardware and software versions. Because of the large management overhead though, this method should only be used on very small networks.
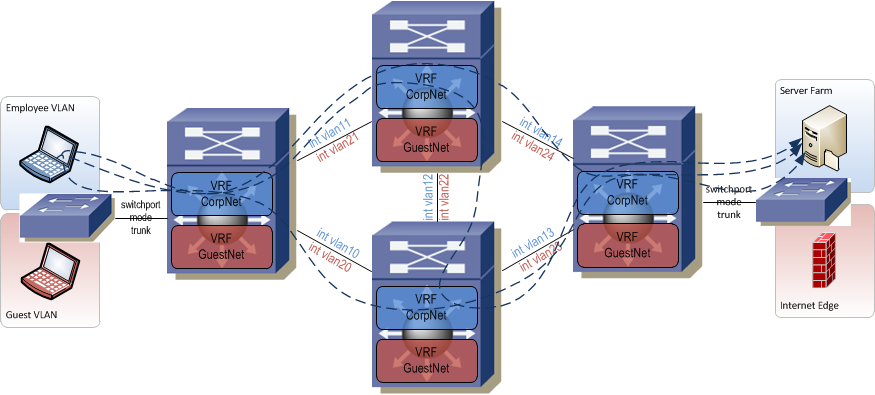
A more scalable alternative to hop-by-hop is to encapsulate each VRF's traffic inside a tunnel. Since a tunnel can be provisioned directly between two edge routers, nothing needs to be touched in the core of the network. In fact, the VRFs don't even need to be provisioned in the core of the network (assuming there are no edge devices connected to the core). This simplifies the provisioning of paths through the network and eliminates the risk of a mistake being made on a core router during provisioning. If provisioned correctly, a tunnel also provides built-in path redundancy (unlike hop-by-hop which you have to manually account for). Assume an active tunnel is following this path through the network: A->B->C and that router B fails. As long as there is an alternate path through the network between the two tunnel endpoint addresses on A and C, the tunnel will re-route and the VRF traffic inside the tunnel will continue to flow. One caveat with tunneling is that not all devices perform tunneling in hardware and some don't even support protocols such as GRE at all. You tunnel endpoints need to support GRE and depending on your traffic load, should perform GRE functions in silicon.
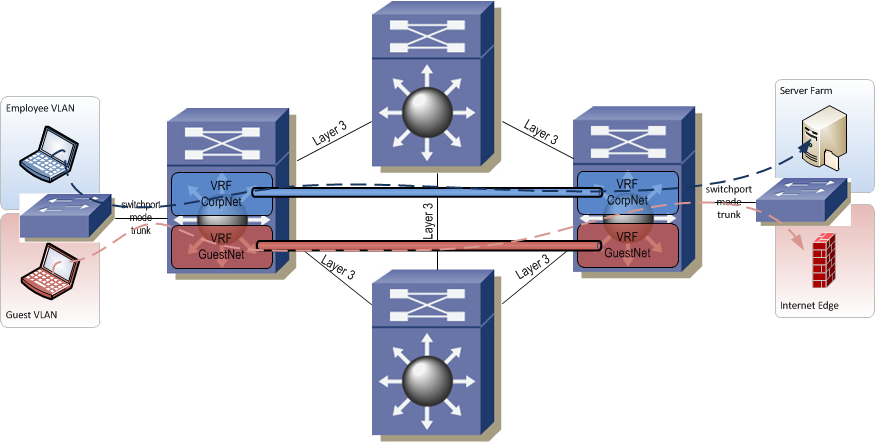
The final and most scalable method is full on MPLS. MPLS dynamically creates paths from edge router to edge router for transporting VRF traffic through the network. Although MPLS is the most scalable it is also the most complex. An MPLS network requires BGP and LDP (Label Distribution Protocol) both of which must be well understood by the network provisioning and operations teams. MPLS also has the strictest hardware requirements of any of the path separation methods. Network devices must be capable of running BGP and LDP, must have enough memory on board to handle all the entries in the routing and label forwarding tables, and should be capable of label switching in silicon for best performance.
The hop-by-hop and tunnel methods are what's known as "VRF lite" — you're using VRFs but without full-blown MPLS to tie everything together. VRF lite is often found in enterprise networks where the number of VRFs in play are still manageable using these manual path isolation methods.
Shared Services⌗
Shared services are things like DNS, DHCP, and Internet access that are typically common to all VRFs. Rather than running a set of DNS servers and a set of DHCP servers for each virtual network, you stand up one set of servers that can service everyone. Internet access is the same. Running multiple Internet services is costly and time consuming so it's usually shared among all VRFs.
Shared services are typically located in their own little module that hangs off the edge of the network. This module is one of the trickiest parts of a VRF-enabled network because it's really easy to accidentally allow traffic to leak between VRFs if proper care is not taken. Since the servers and Internet edge devices that sit in the shared services module need to talk to end devices in all the VRFs, this module needs to contain routes for all of the VRFs. It would be really easy to accidentally allow routes from VRF A to be advertised through the shared services module into VRF B (and vice-versa) thus allowing devices in A and B to freely communicate.
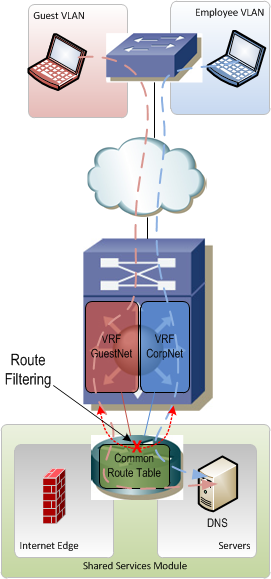
Another big challenge with shared services is the fact that VRFs can have overlapping IP address space. It becomes increasingly difficult to provide services like DNS and DHCP on a single server for overlapping IP networks. In this case it may be necessary to actually have multiple servers that serve a subset of VRFs or even just an individual VRF. The "shared" in "shared services" now refers more to the shared infrastructure which connects these servers to the rest of the network rather than the servers themselves being shared.
Final Word⌗
This is the first post in what I hope to turn into a short series on Virtual Routing and Forwarding. Future posts will discuss how to configure VRFs, practical applications for VRFs in an enterprise network, and go into more detail on shared services.