Lab: iBGP and OSPF Traffic Engineering
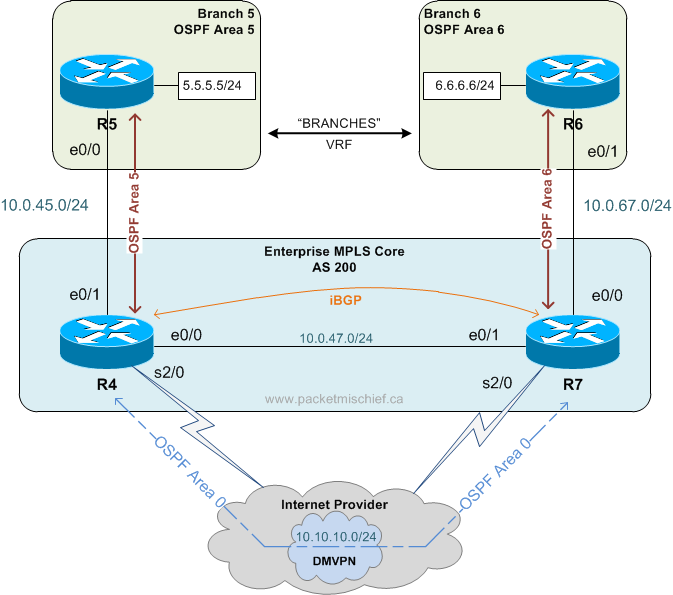
Here's the scenario: An enterprise network with an MPLS core and two branch locations connected to their own Provider Edge (PE) router. In addition to the MPLS link, the PEs are also connected via a DMVPN tunnel. The PEs are peering via iBGP (of course) and are also OSPF neighbors on the DMVPN. Both Customer Edge (CE) routers at the branch are OSPF neighbors with their local PE.
Task: Use the high speed MPLS network as the primary path between the CE routers and only use the DMVPN network if the MPLS network becomes unavailable.
Question: Is the solution as simple as adjusting the Admin Distance (AD) so that the iBGP routes are more preferred?
Default State⌗
The obvious first issue is the default AD for iBGP (200) is higher than the default AD of OSPF (110) which means the OSPF path over the DMVPN is going to be preferred. This is confirmed if we do a traceroute from R5 to R6:
R5#traceroute 6.6.6.6 source lo5
1 10.0.45.4 2 msec 0 msec 1 msec
2 10.10.10.7 17 msec 17 msec 17 msec
3 10.0.67.6 18 msec * 18 msec
I know it's hard to read a traceroute from a network you just saw for the first time and to try and correlate it back to which IP belongs to which router and which interface. A dead giveaway here is that there's no MPLS label shown in the traceroute output. Take my word for it: any traceroute I show here that doesn't have an MPLS label in the output is going via the DMVPN.
For the purposes of this post the details of the DMVPN aren't relevant so I won't be explaining them at all. All that is relevant is that the DMVPN is providing a non-MPLS path between the PEs over which they're running an IGP which in this case is OSPF.
The first step in achieving the task is adjusting the AD so iBGP is more preferred.
Adjust Admin Distance⌗
I've chosen to raise the OSPF AD on each PE to 201.
R4:
router ospf 10 vrf BRANCHES
router-id 10.10.10.4
distance 201 10.10.10.7 0.0.0.0
R7:
router ospf 10 vrf BRANCHES
router-id 10.10.10.7
distance 201 10.10.10.4 0.0.0.0
Note how I also explicitly set the router-id. This is a smart idea when modifying the AD of routes received from specific neighbors because neighbors are identified by their router-id and you don't want the router-id to change when the remote router is reloaded - it would invalidate the AD modifications.
Why did I change the AD only for routes received from a specific neighbor and not for all OSPF routes?
Let's look at it from R7's point of view. First R7 receives the 6.6.6.0/24 route from R6 (OSPF AD 201). Now there's a race. If R7 advertises the route to R4 via iBGP and R4 installs the route in the routing table before R4 receives the route via OSPF, then everything is fine. However, if R4 receives the route via OSPF first then this happens:
- R4 receives the route from R7 via OSPF and installs it into the routing table (the RIB)
- As per its existing configuration, it redistributes the route into BGP
- R7 learns 6.6.6.0/24 from R4 via BGP with an AD of 200
- The BGP route with AD of 200 is better than the OSPF route with AD of 201 so R7 installs the BGP route to 6.6.6.0/24.
- As per its existing configuration, R7 redistributes the BGP route into OSPF and continues to advertise it to R4. There's now a routing loop for 6.6.6.0/24.
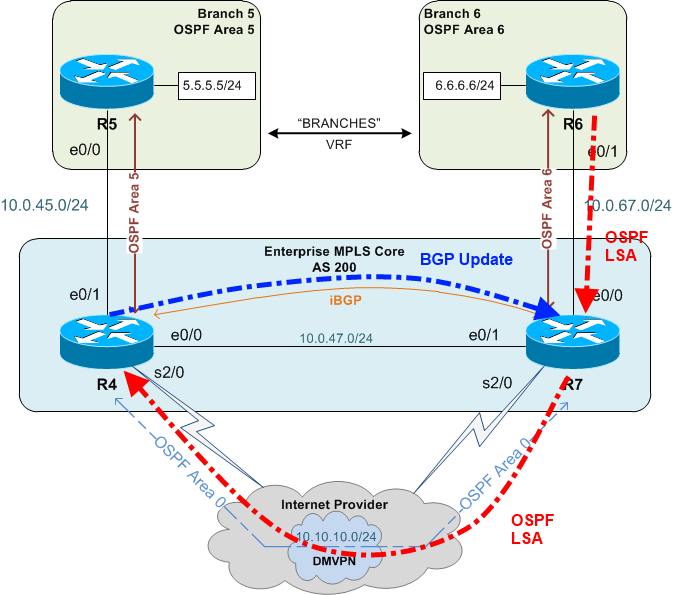
Because of this, I only modified the AD of OSPF routes learned via the DMVPN neighbor. This keeps the routes learned from the CE at the default AD of 110 meaning it will always be preferred over the same route learned via iBGP.
What are the results from changing the AD?
R5#traceroute 6.6.6.6 source lo5
1 10.0.45.4 2 msec 0 msec 1 msec
2 10.10.10.7 17 msec 17 msec 17 msec
3 10.0.67.6 18 msec * 18 msec
No change! What's going on?! The prefix exists in the BGP RIB so it should work:
R4#show bgp vpnv4 unicast all
[..]
Network Next Hop Metric LocPrf Weight Path
Route Distinguisher: 200:1 (default for vrf BRANCHES)
* 6.6.6.6/32 10.10.10.7 1011 32768 ?
* i 10.1.7.7 11 100 0 ?
Ahh, but there's the problem: BGP has chosen the locally originated route as the best route (note the weight of 32768 which is a strong hint the route is locally originated) and not the route learned from the iBGP neighbor. Why is that?
- Remember I said earlier that trouble happens when OSPF wins the race of which protocol will advertise the route from R7 to R4 first
- Remember that OSPF is being redistributed into BGP on the PEs
- Remember the BGP best-path decision process: the weight attribute is the first thing that is compared (putting aside the pre-bestpath cost community attribute for now); higher weight wins
What happens here is that 6.6.6.0/24 is learned via OSPF on R4, redistributed into BGP and then also learned via BGP from R7. The weight of the redistributed route is higher than the iBGP learned route so it's chosen as the best BGP route. Finally, since this route came from the routing table to begin with (by way of redistribution) it cannot be put back into the routing table because that would be some sort of weird inception thing so we end up with the OSPF route being the route that lives in the RIB and hence our traceroute continues to follow the DMVPN path.
This is a good example of why I diagrammed the process of how IOS chooses which routes to put into the RIB/FIB — in this case here it's not just AD that plays a part but also the best-path decision process that one of the protocols goes through.
What's needed here is to modify the BGP weight attribute of the route received from the BGP peer so that that route is preferred over the locally redistributed route.
Modify the Weight Attribute⌗
Here I change the weight of the route received from the BGP neighbor.
R4:
router bgp 200
address-family vpnv4
neighbor 10.1.7.7 weight 35000
R7:
router bgp 200
address-family vpnv4
neighbor 10.1.4.4 weight 35000
I chose to modify the weight of all routes received from the neighbor which may be a bit heavy-handed but it achieves the goal. I modified the weight under the vpnv4 address family because the routes are being advertised by MP-BGP as type vpnv4.
What's wrong with this picture now? Well, I've created an issue that's kinda-sorta like the earlier one with the OSPF AD.
- R7 advertises 6.6.6.0/24 to R4 via OSPF; OSPF on R4 redistributes into BGP; R4 advertises 6.6.6.0/24 to R7 via BGP.
- R7 also redistributes 6.6.6.0/24 from OSPF into BGP and advertises the route to R4 via BGP.
- R7 now has two copies of 6.6.6.0/24 in the BGP table: the one that was locally redistributed from OSPF and the one it just learned from R4.
- R7 executes the BGP best-path decision process. Since the weight of the route received from R4 (35000) is greater than the weight of the redistributed route (32768), the R4 route is deemed best.
- Since R7 has decided that the route via R4 is best, it sends a withdrawal message to R4 for the route that it advertised in step 2 (split horizon in action).
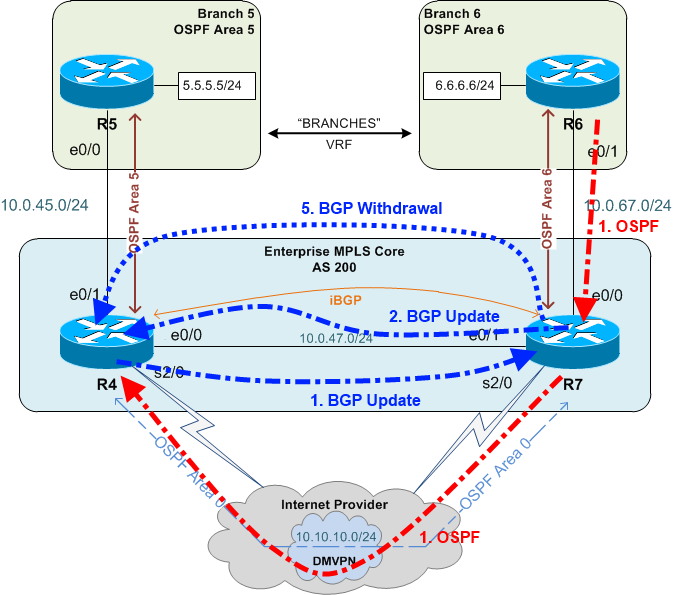
At this point R4 only has one route to 6.6.6.0/24 — the OSPF route via the DMVPN — because R7 has pulled its BGP advertisement. Traceroutes from R5 to R6 still transit the DMVPN.
What's needed now is to prevent each PE from learning its locally attached CE routes from the other PE.
Blocking CE Routes From the BGP Neighbor⌗
There are multiple ways to filter routes in BGP. I chose a method that is straightforward and logical to me which is to create a prefix-list which matches the prefixes and use that prefix-list in a route-map to deny BGP updates about those prefixes.
R4:
ip prefix-list LOCAL_CE_ROUTES seq 5 permit 5.5.5.0/24
route-map MP-BGP-IN deny 10
match ip address prefix-list LOCAL_CE_ROUTES
route-map MP-BGP-IN permit 99
router bgp 200
address-family vpnv4
neighbor 10.1.7.7 route-map MP-BGP-IN in
R7:
ip prefix-list LOCAL_CE_ROUTES seq 5 permit 6.6.6.0/24
route-map MP-BGP-IN deny 10
match ip address prefix-list LOCAL_CE_ROUTES
route-map MP-BGP-IN permit 99
router bgp 200
address-family vpnv4
neighbor 10.1.4.4 route-map MP-BGP-IN in
Remember: this is a lab task. The solution doesn't have to be perfect. Aim for simplicity and something that's logical to you; something you will not have to struggle with in the actual lab when your brain is totally scrambled on adrenaline and lack of sleep.
For anyone that is really paying attention (and I applaud you), you might've noticed that applying the filter as I did above would also solve the earlier OSPF routing loop issue. With the filter in place, I could've simplified my OSPF config and changed the OSPF AD for all routes and not just the routes learned from the other PE. I'm a linear thinker though and I admit, I didn't even spot this overlap until I had written most of this blog post. It goes to show that there is often more than one way to achieve the desired result.
Final Results⌗
After all that, have we achieved the task!? Let's do some traceroutes from the CEs.
R5#traceroute 6.6.6.6 sour lo5
1 10.0.45.4 1 msec 2 msec 0 msec
2 10.0.67.7 [MPLS: Label 28 Exp 0] 1 msec 1 msec 1 msec
3 10.0.67.6 1 msec * 1 msec
Looks good! (MPLS label present; we're traversing the MPLS core)
Looking from the other side:
R6#traceroute 5.5.5.5 source lo6
1 10.0.67.7 1 msec 1 msec 1 msec
2 10.0.45.4 [MPLS: Label 23 Exp 0] 1 msec 1 msec 1 msec
3 10.0.45.5 1 msec * 2 msec
Also good.
Remember: Always verify from both ends. Just because something works a certain way on one device, doesn't mean the other devices are working the same way.
Now fail the MPLS core and test.
R5#traceroute 6.6.6.6 sour lo5
1 10.0.45.4 6 msec 5 msec 5 msec
2 10.10.10.7 17 msec 18 msec 17 msec
3 10.0.67.6 17 msec * 18 msec
R6#traceroute 5.5.5.5 source lo6
1 10.0.67.7 1 msec 1 msec 1 msec
2 10.10.10.4 18 msec 18 msec 17 msec
3 10.0.45.5 18 msec * 17 msec
Good. Now restore MPLS and test.
Remember: Test the network again after recovery from the failure! It's not uncommon to find that the network will reconverge in an unexpected way when the failure is repaired.
R5#traceroute 6.6.6.6 sour lo5
1 10.0.45.4 1 msec 2 msec 0 msec
2 10.0.67.7 [MPLS: Label 28 Exp 0] 1 msec 1 msec 1 msec
3 10.0.67.6 1 msec * 1 msec
R6#traceroute 5.5.5.5 source lo6)
1 10.0.67.7 1 msec 1 msec 1 msec
2 10.0.45.4 [MPLS: Label 23 Exp 0] 1 msec 1 msec 1 msec
3 10.0.45.5 1 msec * 2 msec
All good!
Thoughts⌗
The original question was this: Is the solution as simple as adjusting the Admin Distance (AD) so that the iBGP routes are more preferred?
1700 words later, the obvious answer is no. In order to achieve this task, it was critical to understand how redistribution works, how BGP makes best-path decisions, and how to manipulate BGP attributes. We then had to deal with each of these issues in order to successfully achieve the task.
Update: As a reader pointed out, an OSPF sham link between R4 and R7 would also solve this task. However, it's often the case where you're given restrictions in the lab about what you're allowed to do. In the case of the practice lab where this example came from, there was a restriction about creating any new IP addresses. Since a sham link requires creating a new loopback interface in the VRF to act as the sham link end point, I implemented the long complicated solution above.
A companion post to this one is Choosing a Route: Order of Operations which talks about the decision criteria that IOS uses when installing a route into the RIB (and then the FIB).
Thanks for hanging in and reading all the way through.