Building a Scalable Document Pre-Processing Pipeline
This article was originally posted on the Amazon Web Services Architecture blog.
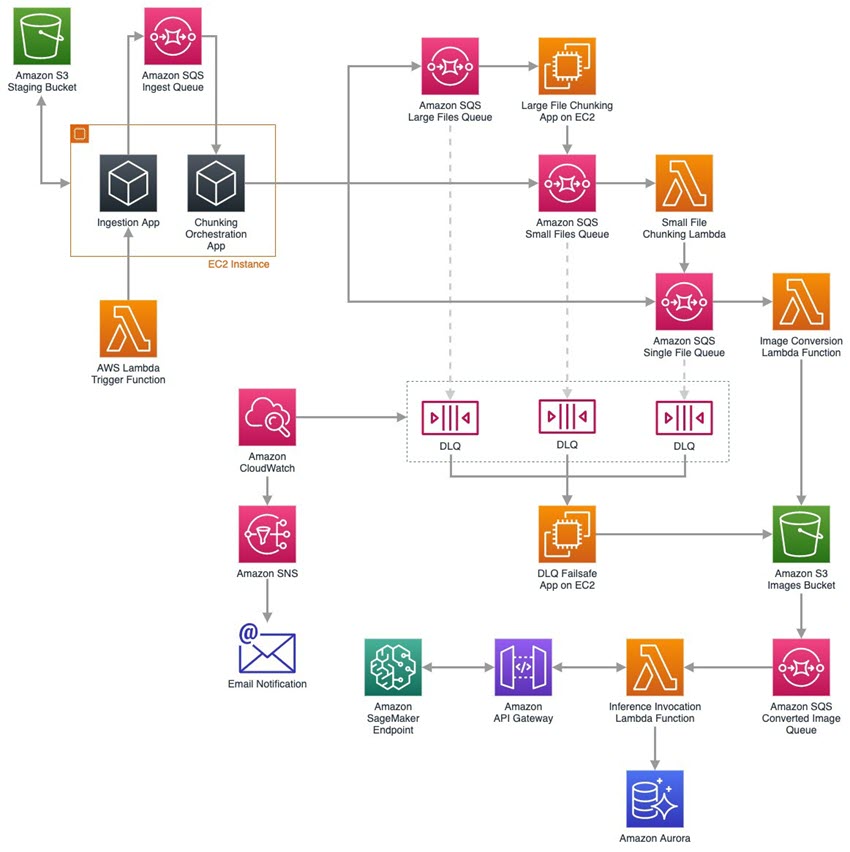
In a recent customer engagement, Quantiphi, Inc., a member of the Amazon Web Services Partner Network, built a solution capable of pre-processing tens of millions of PDF documents before sending them for inference by a machine learning (ML) model. While the customer's use case--and hence the ML model--was very specific to their needs, the pipeline that does the pre-processing of documents is reusable for a wide array of document processing workloads. This post will walk you through the pre-processing pipeline architecture.
Architectural goals⌗
Quantiphi established the following goals prior to starting:
- Loose coupling to enable independent scaling of compute components, flexible selection of compute services, and agility as the customer's requirements evolved.
- Work backwards from business requirements when making decisions affecting scale and throughput and not simply because "fastest is best". Scale components only where it makes sense and for maximum impact.
- Log everything at every stage to enable troubleshooting when something goes wrong, provide a detailed audit trail, and facilitate cost optimization exercises by identifying usage and load of every compute component in the architecture.
Document ingestion⌗
The documents are initially stored in a staging bucket in Amazon Simple Storage Service (Amazon S3). The processing pipeline is kicked off when the "trigger" Amazon Lambda function is called. This Lambda function passes parameters such as the name of the staging S3 bucket and the path(s) within the bucket which are to be processed to the "ingestion app".
The ingestion app is a simple application that runs a web service to enable triggering a batch and lists documents from the S3 bucket path(s) received via the web service. As the app processes the list of documents, it feeds the document path, S3 bucket name, and some additional metadata to the "ingest" Amazon Simple Queue Service (Amazon SQS) queue. The ingestion app also starts the audit trail for the document by writing a record to the Amazon Aurora database. As the document moves downstream, additional records are added to the database. Records are joined together by a unique ID and assigned to each document by the ingestion app and passed along throughout the pipeline.
Chunking the documents⌗
In order to maximize grip and control, the architecture is built to submit single-page files to the ML model. This enables correlating an inference failure to a specific page instead of a whole document (which may be many pages long). It also makes identifying the location of features within the inference results an easier task. Since the documents being processed can have varied sizes, resolutions, and page count, a big part of the pre-processing pipeline is to chunk a document up into its component pages prior to sending it for inference.
The "chunking orchestrator" app repeatedly pulls a message from the ingest queue and retrieves the document named therein from the S3 bucket. The PDF document is then classified along two metrics:
- File size
- Number of pages
We use these metrics to determine which chunking queue the document is sent to:
- Large: Greater than 10MB in size or greater than 10 pages
- Small: Less than or equal to 10MB and less than or equal to 10 pages
- Single page: Less than or equal to 10MB and exactly one page
Each of these queues is serviced by an appropriately sized compute service that breaks the document down into smaller pieces, and ultimately, into individual pages.
- Amazon Elastic Cloud Compute (EC2) processes large documents primarily because of the high memory footprint needed to read large, multi-gigabyte PDF files into memory. The output from these workers are smaller PDF documents that are stored in Amazon S3. The name and location of these smaller documents is submitted to the "small documents" queue.
- Small documents are processed by a Lambda function that decomposes the document into single pages that are stored in Amazon S3. The name and location of these single page files is sent to the "single page" queue.
The Dead Letter Queues (DLQs) are used to hold messages from their respective size queue which are not successfully processed. If messages start landing in the DLQs, it's an indication that there is a problem in the pipeline. For example, if messages start landing in the "small" or "single page" DLQ, it could indicate that the Lambda function processing those respective queues has reached its maximum run time.
An Amazon CloudWatch Alarm monitors the depth of each DLQ. Upon seeing DLQ activity, a notification is sent via Amazon Simple Notification Service (Amazon SNS) so an administrator can then investigate and make adjustments such as tuning the sizing thresholds to ensure the Lambda functions can finish before reaching their maximum run time.
In order to ensure no documents are left behind in the active run, there is a failsafe in the form of an Amazon EC2 worker that retrieves and processes messages from the DLQs. This failsafe app breaks a PDF all the way down into individual pages and then does image conversion.
For documents that don.t fall into a DLQ, they make it to the "single page" queue. This queue drives each page through the "image conversion" Lambda function which converts the single page file from PDF to PNG format. These PNG files are stored in Amazon S3.
Sending for inference⌗
At this point, the documents have been chunked up and are ready for inference.
When the single-page image files land in Amazon S3, an S3 Event Notification is fired which places a message in a "converted image" SQS queue which in turn triggers the "model endpoint" Lambda function. This function calls an API endpoint on an Amazon API Gateway that is fronting the Amazon SageMaker inference endpoint. Using API Gateway with SageMaker endpoints avoided throttling during Lambda function execution due to high volumes of concurrent calls to the Amazon SageMaker API. This pattern also resulted in a 2x inference throughput speedup. The Lambda function passes the document's S3 bucket name and path to the API which in turn passes it to the auto scaling SageMaker endpoint. The function reads the inference results that are passed back from API Gateway and stores them in Amazon Aurora.
The inference results as well as all the telemetry collected as the document was processed can be queried from the Amazon Aurora database to build reports showing number of documents processed, number of documents with failures, and number of documents with or without whatever feature(s) the ML model is trained to look for.
Summary⌗
This architecture is able to take PDF documents that range in size from single page up to thousands of pages or gigabytes in size, pre-process them into single page image files, and then send them for inference by a machine learning model. Once triggered, the pipeline is completely automated and is able to scale to tens of millions of pages per batch.
In keeping with the architectural goals of the project, Amazon SQS is used throughout in order to build a loosely coupled system which promotes agility, scalability, and resiliency. Loose coupling also enables a high degree of grip and control over the system making it easier to respond to changes in business needs as well as focusing tuning efforts for maximum impact. And with every compute component logging everything it does, the system provides a high degree of auditability and introspection which facilitates performance monitoring, and detailed cost optimization.