Virtualizing the OpenBSD Routing Table
The OpenBSD routing table can be carved into multiple virtual routing tables allowing complete logical separation of attached networks. This article gives a brief overview of rtables and explains how to successfully leak traffic between virtual routing domains.
The ability to virtualize the routing table in OpenBSD first appeared in version 4.6. Since then the functionality has matured nicely with support for virtual routing tables now present in userland tools such as dhclient(8) and dhcpd(8) and in the routing protocol daemons ripd(8), ospfd(8), and bgpd(8). Kernel side, pf(4) has been extended to handle filtering of packets based on the routing table they came in on as well as being able to move packets between routing tables. This article will concentrate on the latter with examples of how to setup separate routing tables and leak traffic between them successfully.
Using separate routing tables is similar to using VRFs in Cisco IOS or routing instances in Juniper's JUNOS. Multiple routing tables are created each of which contain their own forwarding and ARP information. In OpenBSD, each routing table is called an "rtable". Network interfaces can be bound to an rtable which causes traffic going through the interface to be forwarded based on the information present in that rtable. When one or more interfaces are bound to an rtable, the rtable and all of the interfaces bound to it are called a routing domain, or "rdomain".
Basic Configuration⌗
Creating an rtable is done using route(8) with the -T argument.
route -T 1 add 0.0.0.0/0 192.168.1.1
This creates rtable 1 if it doesn't already exist and adds a default route to it.
Interfaces are bound to an rtable using ifconfig(8) with the "rdomain" keyword.
ifconfig vic1 rdomain 1
This binds the vic1 interface to rtable 1.
To execute a command within a non-default rtable, use the route(8) command with the exec keyword.
route -T 1 exec telnet 10.5.3.29
This executes the telnet command within rtable 1. Certain commands such as ping(8) and arp(8) have their own command line arguments that will place them into an rtable (the -V argument in this case).
Setting up rdomains⌗
By default, all interfaces on an OpenBSD host belong to rdomain 0. Traffic can flow freely between all interfaces (assuming the pf(4) ruleset allows it) without any special handling. Similarly, traffic can flow between all interfaces in the same non-default routing domain without any special handling (again, as long as the pf(4) ruleset passes this traffic).
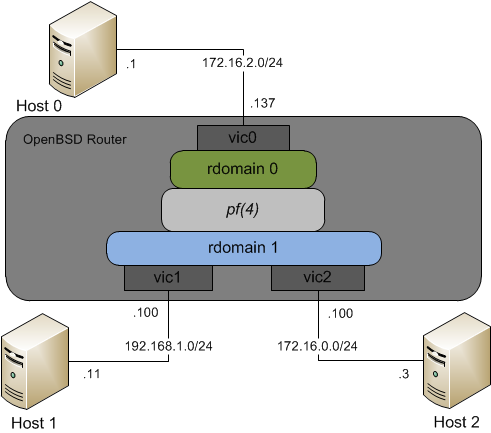
In this network, Host 1 and Host 2 both belong to rdomain 1. Routing domain 1 has routes to the 192.168.1/24 and 172.16.0/24 networks because they are directly attached so traffic between the two is forwarded without any special consideration. Host 1 and 2 cannot talk to Host 0 because Host 0 is connected to a separate routing domain.
As shown in the picture, pf(4) is used to connect routing domains. This is really powerful because pf(4) allows for very fine-grained packet matching which means you can be as specific or broad as you want when it comes to what traffic you want to pass between rdomains. Sending traffic between rdomains is done by using the rtable keyword in pf.conf.
pass in on vic1 to 172.16.2.0/24 rtable 0
pass out on vic0
This is the basic ruleset needed to allow Host 1 to initiate a connection to Host 0.
The rtable must be specified on the rule that matches traffic inbound to the OpenBSD router. As stated in the pf.conf(5) man page, the resulting route lookup will only work correctly if the rtable is specified on the inbound rule. This ruleset is not enough for traffic to flow bidirectionally. We also have to look at the routing entries within the source and destination routing domains.
The source routing domain, in this case rdomain 1, is easy. pf(4) will magically handle taking the packets out of rdomain 1 and sending them to rdomain 0 — we do not need a route for 172.16.2/24 in rtable 1. Reverse traffic is different. Routing domain 0 requires a route be present for 192.168.1/24. The next-hop for this route isn't really important, what's important is that it's present in the rtable. If a route isn't present, then the route lookup will fail before pf(4) has a chance to move the packet into rdomain 1 and the return traffic will be dropped. Note that the route doesn't have to be exactly 192.168.1/24, it could be 192.168/16 or even 0.0.0.0/0 — the important part is that there is some kind of route in rtable 0 that will match the network in rdomain 1.
route -T 0 add 192.168.1/24 -iface 172.16.2.137
This is kind of a cheat. It creates a route for 192.168.1/24 as a connected route on the rdomain 0 interface. Obviously this isn't correct, but it doesn't really matter. It achieves the goal of getting a route into rtable 0. Host 1 can now successfully talk to Host 0.
An alternative to creating a "connected" route is to set the next-hop of the 192.168.1/24 route to the loopback IP.
route -T 0 add 192.168.1/24 127.0.0.1
The loopback interface provides a really convenient place to point your reverse path routes.
The caveat with this is that pf(4) must be active on the loopback interface you create. The default pf.conf ruleset contains "set skip on lo" which disables pf(4) on each loopback interface and will result in return traffic being dropped. Be sure that your loopback isn't being "skipped".
The same idea works between two non-default routing domains.
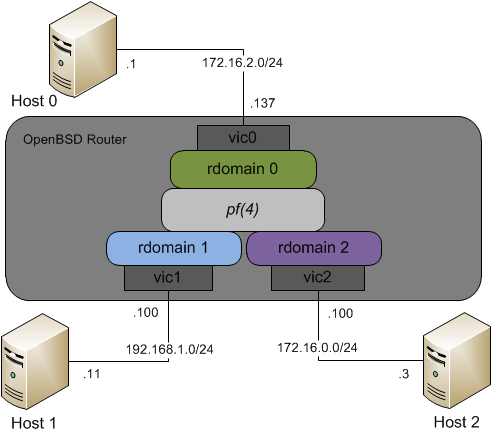
Creating a loopback interface in rdomain 2 so that Host 1 can talk to Host 2 would look like:
ifconfig lo2 rdomain 2 127.0.0.1
route -T 2 add 192.168.1/24 127.0.0.1
Since lo2 is created inside rdomain 2, the IP address assigned to it doesn't conflict with lo0 in rdomain 0.
Another caveat with the pf(4) ruleset is that the states that get created by the rule that specifies the rtable must be "floating".
If you've changed the "state-policy" option in your pf.conf from the default of "floating" then you must use the "floating" keyword in your inbound rule.
set state-policy if-bound
pass in on vic1 to 172.16.2.0/24 rtable 0 keep state (floating)
pass out on vic0
All of the above guidance also applies if you're doing NAT on the outbound interface.
pass in on vic1 to 172.16.2.0/24 rtable 0
pass out on vic0 nat-to vic0
This ruleset would hide the 192.168.1/24 network from hosts in rdomain 0 by translating the source 192.168.1.x IP to the IP address on the vic0 interface. This might be necessary if there's already a 192.168.1 network in rdomain 0. Even though you're doing NAT, you still need a route in rdomain 0 that points back to the real source network (192.168.1/24) in rdomain 1.
Sample Use Cases⌗
Routing domains can be used to isolate a test/dev network from production.
In the sample network from earlier, rdomain 0 could be the production network with production servers and the users connected to it. Routing domain 1 could be a test network where applications and systems are put through testing before being moved into rdomain 0. In order to prevent the test systems from possibly affecting the production systems, they could be isolated in their own routing domain, ensuring that test traffic cannot get into the production network. In fact, the test network could even use the same IP addresses as the production network without them stepping on each other. A pf(4) ruleset could be written that lets management/administrative traffic from the production network into test. A ruleset could also be written that allows the test systems to talk to a specific management or file server in the production network. If overlapping IP space is used, traffic between the rdomains must be NAT'd as outlined above.
Routing domains can also be used to connect to multiple ISPs. Since userland tools such as dhclient(8) work properly within routing domains, each ISP interface could be put into its own routing domain without the risk of conflicting default routes.
Here if vic1 is connected to ISP#1 and vic2 is connected to ISP#2, the pf(4) ruleset would control which ISP connection to use when users in rdomain 0 connect to the Internet. This provides a much more elegant solution than the outbound load balancing example I wrote about in the PF User's Guide.
The only shared component of a multiple-dhclient(8) setup is the resolv.conf(5) file. Each copy of dhclient(8) will update the file as it renews its lease.
Conclusion⌗
By virtualizing the OpenBSD routing table you can create virtual routers and/or firewalls within the same physical OpenBSD machine. Networks can be safely isolated from each other without having to worry about traffic crossing network boundaries or IP addresses overlapping. Routing domains can be created by binding one or more interfaces to a routing table so that all traffic crossing those interfaces is automatically forwarded based on the routes present in the virtualized routing table. Traffic can be leaked between routing domains by using the granular pf(4) packet matching syntax to allow policy-based communication between routing domains.