Benchmarking OpenBSD: UP vs MP for "make build"
I used to have a machine sitting around that I would power up whenever I needed to build a new OpenBSD kernel or rebuild the source tree due to a patch or a new version of the OS being released. Eventually I moved that machine into a VirtualBox virtual machine running on my desktop. Recently I moved that VM into VMWare's free ESXi hypervisor running on some pretty decent hardware. It got me wondering how much I could lower compile times by adjusting how many vCPUs were allocated to the VM.
Disclaimer⌗
These tests are not exactly scientific. For example, I didn't take care between tests to ensure the buffers on the RAID card were flushed or that the file system buffer cache was cleared. However, I'm comfortable accepting whatever margin for error that this has introduced. I'm interested to see how I can eek out significant reductions in compile time and I don't believe the hardware or file system buffers will really have that big of an impact.
Test Environment⌗
This is what I was working with to do these tests.
- Test machine running OpenBSD 4.9 building OpenBSD 4.9 sources (/usr/src)
- Test machine is a VM running on VMWare ESXi 4.1u1
- The physical server has an Intel E5620 Xeon CPU (quad core)
- The ESXi storage is on top of two 7200 RPM SATA drives in a hardware mirror
- The VM was allocated 512M of RAM for every test
- There was only 1 other VM running on the ESXi host and it was idle
- The test machine is dedicated to building the source tree; it does not run any other services or apps
Testing "make build"⌗
I ran a number of tests each time changing either the number of vCPUs or number of concurrent make(1) jobs using the -j argument. I established a baseline number by doing a run using 1 vCPU and the non multi-processor kernel (bsd). From there I increased to 2 vCPUs and then to 4 and switched to the MP kernel (bsd.mp). Unfortunately, since I'm using the free version of ESXi, 4 vCPUs is as far as I could take the tests.
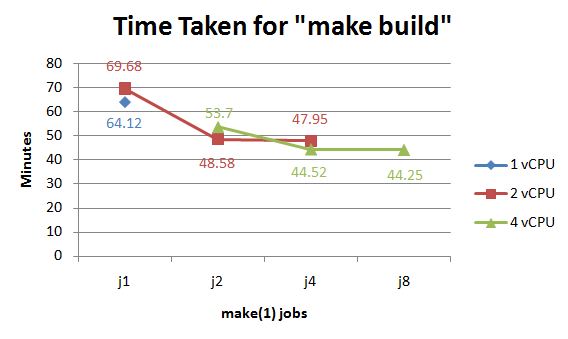
I found that when I matched the number of make(1) jobs to the number of vCPUs that I got the best results. This makes sense since it provides work for each CPU. I also tested with more jobs than the number of CPUs but as the graph shows the results there were insignificant. I also found that the difference between the 2 CPU and 4CPU test was pretty minimal (only 4 minutes faster). This makes me believe that at 4 CPUs, the system probably becomes more I/O bound and not CPU bound.
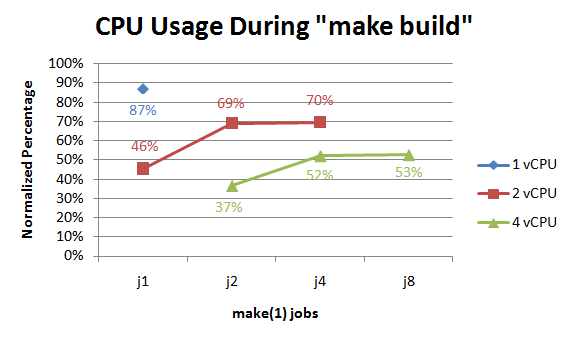
I suppose this graph supports that theory. As the amount of CPU power goes up, the normalized usage (ie, the total CPU used as a percentage divided by the number of vCPUs) peaks lower and lower.
Testing by Building GENERIC⌗
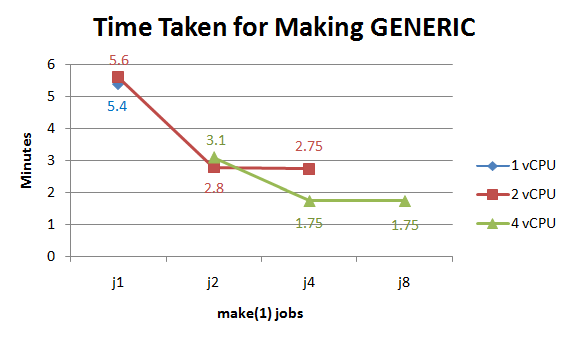
During the testing I also recorded the time taken to build only the GENERIC kernel. The numbers are interesting because unlike during "make build", there are significant gains when jumping from 2 CPUs to 4 (36% decrease in time at j4).
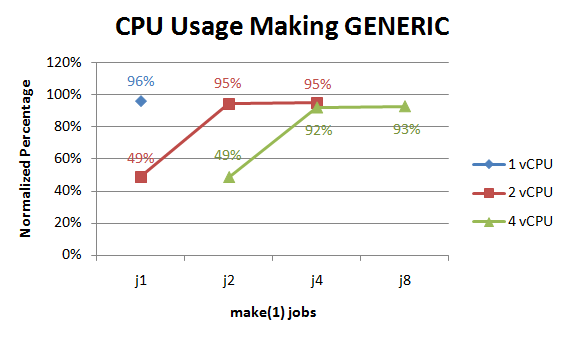
The CPU usage seems to indicate that compiling GENERIC is much more CPU bound than doing a "make build" since the normalized usage stays quite high in all tests (as long as there's enough make(1) jobs to keep each CPU busy).
What's the Point of All This?⌗
Well the point was not to analyze or critique the characteristics of a "make build" or kernel compile. Really, who cares if it's I/O or CPU or something-else bound. All I care about is what combination of virtual machine configuration and make(1) jobs gives me the quickest compile times. It seems like on my system, based on the limits of only being able to test up to 4 vCPUs, that 4 vCPUs and make -j4 provides the lowest time. I suppose it's not surprising that the highest number of CPUs equates to the lowest compile time. What I thought was surprising was how little decrease in time there was in the 4 CPU configuration vs 2 CPU.