Five Functional Facts about FabricPath
FabricPath is Cisco's proprietary, TRILL-based technology for encapsulating Ethernet frames across a routed network. Its goal is to combine the best aspects of a Layer 2 network with the best aspects of a Layer 3 network.
- Layer 2 plug and play characteristics
- Layer 2 adjacency between devices
- Layer 3 routing and path selection
- Layer 3 scalability
- Layer 3 fast convergence
- Layer 3 Time To Live field to drop looping packets
- Layer 3 failure domain isolation
An article on FabricPath could go into a lot of detail and be many pages long but I'm going to concentrate on five facts that I found particularly interesting as I've learned more about FabricPath.
#1 - FabricPath is not a network topology⌗
When I first started learning about FabricPath, I believed that it came with a requirement that your network topology conform to certain rules. While I now know that is not true, there is a common topology that is discussed when talking about network fabrics. It's called the spine+leaf topology.
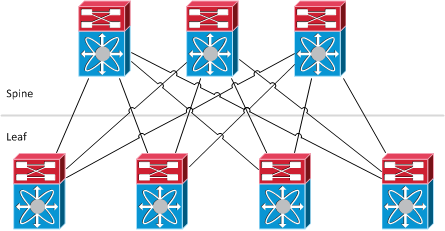
This is similar to a traditional collapsed core design with a few differences.
- When we're talking about a fabric, all links in the network are forwarding. So unlike a traditional network that is running Spanning Tree Protocol, each switch has multiple active paths to every other switch.
- Because all of the links are forwarding, there are real benefits to scaling the network horizontally. Consider if the example topology above only showed (2) spine switches instead of (3). That would give each leaf switch (2) active paths to reach other parts of the network. By adding a third spine switch, not only is the bandwidth scaled but so is the resiliency of the network. The network can lose any spine switch and only drop 1/3rd of its bandwidth. In a traditional network that runs Spanning Tree Protocol, there is no benefit to scaling horizontally like this because STP will only allow (1) link to be forwarding at a time. The investment in an extra switch, transceivers, cables, etc, is just sitting idle waiting for a failure before it can start forwarding packets.
So while the spine+leaf topology is commonly used when discussing FabricPath, it is not a requirement. In fact, even having full-mesh connectivity between spine and leaf nodes as shown in the drawing is not a requirement. You could connect each spine to every other leaf. You could connect spines to other spines or a leaf to a leaf.
According to Cisco, there is a lot of interest from customers about using FabricPath for connecting sites together (ie, as a data center interconnect or for connecting buildings in a campus). An example of that might be a ring topology that connects each of the sites.
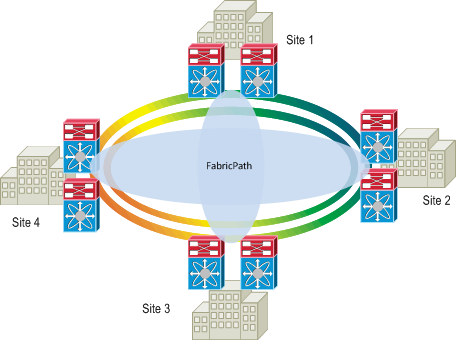
The drawing shows FabricPath being used between the switches that connect to the fiber ring. This is obviously a very different topology than spine+leaf and yet perfectly reasonable as far as FabricPath is concerned.
FabricPath is a method for encapsulating Layer 2 traffic across the network. It does not define or require a specific network topology. The rule of thumb is: if the topology makes sense for regular old IP routing, then it makes sense for FabricPath.
#2 - FabricPath introduces its own unique data plane⌗
In order to achieve the benefits that FabricPath brings over Classical Ethernet, some significant changes needed to be implemented in the data plane of the network. Among these changes include:
- The introduction of a Time To Live field in the frame header which is decremented at each FabricPath hop
- A unique addressing scheme consisting of a 12-bit switch ID which is used to switch frames through the fabric
- A Reverse Path Forwarding check is done on each frame as it enters a FabricPath port (another loop prevention mechanism)
- A new frame header format with these new fields
In order for the hardware platform to switch FabricPath frames without any slowdown, new ASICs are required in the network. On the Nexus 7000, these ASICs are present on the F series I/O modules. It's important to understand that not only do the FabricPath core ports need to be on an F series module but so do the Classic Ethernet edge ports which carry traffic belonging to FabricPath VLANs. This last requirement may impact certain existing environments where downstream devices are connected on M1 or M2 I/O modules.
FabricPath is also supported on the Nexus 5500 running NX-OS 5.1(3)N1(1) or higher. Cisco's documentation isn't exactly clear how FabricPath is implemented on the 5500 series but I've been told 55xx boxes do it in hardware (the original 50xx boxes do not support FabricPath).
#3 - FabricPath does not unconditionally learn every MAC in the network⌗
One of the key issues with scaling modern data centers is that the number of MAC addresses each switch needs to learn is growing all the time. The explosion in growth is due mostly to the increase in virtualization. Consider a top-of-rack, 48-port Classical Ethernet switch that connects to 48 servers. That's 48 MAC addresses that this switch and all the other switches in the network need to learn to send frames to those servers. Now consider that those 48 servers are really VMware vSphere hosts and that each host has 20 virtual machines (an average number, probably low for some environments). That's 960 MAC addresses. Quite an increase. Now multiply that out by however many additional ToR switches are also servicing vSphere hosts. All of a sudden your switches' TCAM doesn't look so big any more.
Since FabricPath continues the Layer 2 adjacency that Classical Ethernet has, it must also rely on MAC address learning to make forwarding decisions. The difference, however, is that FabricPath does not unconditionally learn the MAC addresses it sees on the wire. Instead it does "conversational learning" which means that for MACs that are reachable through the fabric, a FabricPath switch will only learn that MAC if it's actively conversing with a MAC that is already present in the MAC forwarding table.
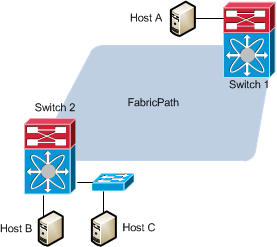
Consider Switch 2 in this example. Host A is reachable through the fabric while B and C are reachable via Classic Ethernet ports. The MACs of B and C are learned on Switch 2 using Classic Ethernet rules which is to say that they are learned as soon as they each send frames into the network. The MAC for A is only learned at Switch 2 if A is sending a unicast packet to B or C and their MAC is already in Switch 2's forwarding table. If A sends a broadcast frame into the network (such as when A is sending an ARP "who-has" request looking for B's MAC), Switch 2 will not learn A's MAC (because the frame from A was not addressed to B, it was a broadcast). Also if A sends a unicast frame for Host D, a host that Switch 2 knows nothing about, Switch 2 will not learn A's MAC (destination MAC must be in the forwarding table to learn the source MAC).
The conversational learning mechanism ensures that switches only learn relevant MACs and not every MAC in the entire domain thus easing the pressure on the finite amount of TCAM in the switch
#4 - FabricPath ports do not have IP addresses⌗
One area where FabricPath gets confusing is when it's referred to as "routing MAC addresses" or "Layer 2 over Layer 3". It's easy to hear terms like "routing" and "Layer 3" and associate that with the most common Layer 3 protocol on the planet — IP — and assume that IP must play a role in the FabricPath data plane. However, as outlined in #2 above, FabricPath employs its own unique data plane and has been engineered to take on the best characteristics of Ethernet at Layer 2 and IP at Layer 3 without actually using either of those protocols. Below is a capture of a FabricPath frame showing that neither Ethernet nor IP are in play.
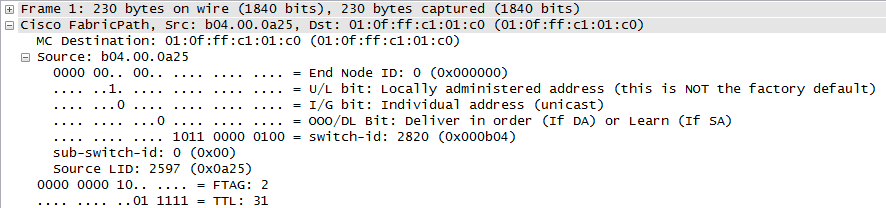
Instead of using IP addresses, an address — called the "switch ID" — is automatically assigned to every switch on the fabric. This ID is used as the source and destination address for FabricPath frames destined to and sourced from the switch. Other fields such as the TTL can also be seen in the capture.
#5 - FabricPath employs Equal Cost Multipath packet forwarding⌗
In Classic Ethernet networks that utilize Spanning Tree Protocol, it's no secret that the bandwidth that's been cabled up in the network is not used efficiently. STP's only purpose in life is to make sure that redundant links in the network are not used during steady-state operation. That's a poor ROI on the cost to put in those links and from a scaling/capacity perspective, it's equally as poor since the network is limited to whatever the capacity is of that one link and cannot employ multiple parallel links. (Ok, you technically can using etherchannel but you understand the point I'm trying to make)
Since FabricPath doesn't use STP in the fabric and because the fabric ports are routed interfaces and therefore have loop prevention mechanisms built-in, all of the fabric interfaces will be in a forwarding state capable of sending and receiving packets. Since all interfaces are forwarding it's possible that there are equal cost paths to a particular destination switch ID. FabricPath switches can employ Equal Cost Multipathing (ECMP) to utilize all equal cost paths.
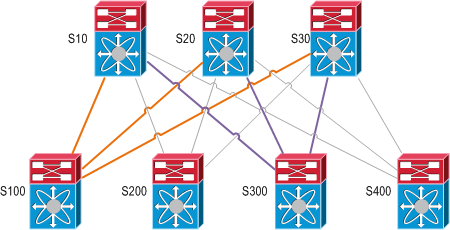
Here S100 has (3) equal cost paths to S300: A path to each of S10, S20, and S30 via the orange links and then from each of those switches to S300 via the purple links.
Much like a regular etherchannel or a CEF multipathing situation, FabricPath ECMP utilizes a hashing algorithm to determine which link a particular traffic flow should be put on. By default the inputs to the hash are:
- Source and destination Layer 3 address
- Source and destination Layer 4 ports (if present)
- 802.1Q VLAN tag
These values are all taken from the original, encapsulated Ethernet frame.
An interesting value-add that FabricPath does is to use the switch's own MAC address as a key for shifting the hashed bits. This shifting prevents polarization of the traffic as it passes through the fabric (ie, prevents every switch from choosing "link #1" all the way through the network due to their hash outputs all being exactly the same). The benefit of this is only realized if there's more than (2) hops between source and destination FabricPath switch.