DCI: Using FabricPath for Interconnecting Data Centers
Here's a topic that comes up more and more now that FabricPath is getting more exposure and people are getting more familiar with the technology: Can FabricPath be used to interconnecting data centers?
For a primer on FabricPath, see my pervious article Five Functional Facts about FabricPath .
FabricPath has some characteristics that make it appealing for DCI. Namely, it extends Layer 2 domains while maintaining Layer 3 — ie, routing — semantics. End host MAC addresses are learned via a control plane, FP frames contain a Time To Live (TTL) field which purge looping packets from the network, and there are no such thing as blocked links — all links are forwarding and Equal Cost Multi-Pathing (ECMP) is used within the fabric. In addition, since FabricPath does not mandate a particular physical network topology, it can be used in spine/leaf architectures within the data center or point-to-point connections between data centers.
Sounds great. Now what are the caveats?
Layer 1 Dependency⌗
As my previous article on FabricPath explains, FabricPath is not an overlay. It has its own unique data plane that operates right on the wire. It does not ride within Ethernet frames and does not ride above IP. It has its own Layer 2 frame format that must be put right onto the wire. Additionally, the control plane protocol — a modified version of Intermediate System to Intermediate System (ISIS) — requires that FP nodes be connected using point-to-point links (no intermediate devices).
Given this requirement, certain WAN technologies preclude the use of FabricPath. For example, transparent LAN services (TLS), Layer 2 extensions, and VPLS are all unsuitable. Layer 1 technologies such as DWDM or dark fiber are ideal and even managed Ethernet over MPLS (EoMPLS) services will work.
Finally, keep in mind that FabricPath adds an additional 16 bytes onto every frame sent through the fabric so the MTU on your DCI links need to accomodate frames of at least 1516 bytes.
First Hop Routing Protocol Localization⌗
I first introduced the concept of FHRP localization in my post about Overlay Transport Virtualization. In a nutshell, FHRP localization optimizes traffic that is sourced from a server in the data center and is destined for something that lives outside the data center. FHRP localization provides the ability for an active HSRP/VRRP gateway in each data center so that the server's traffic doesn't have to cross the DCI link to find its gateway.
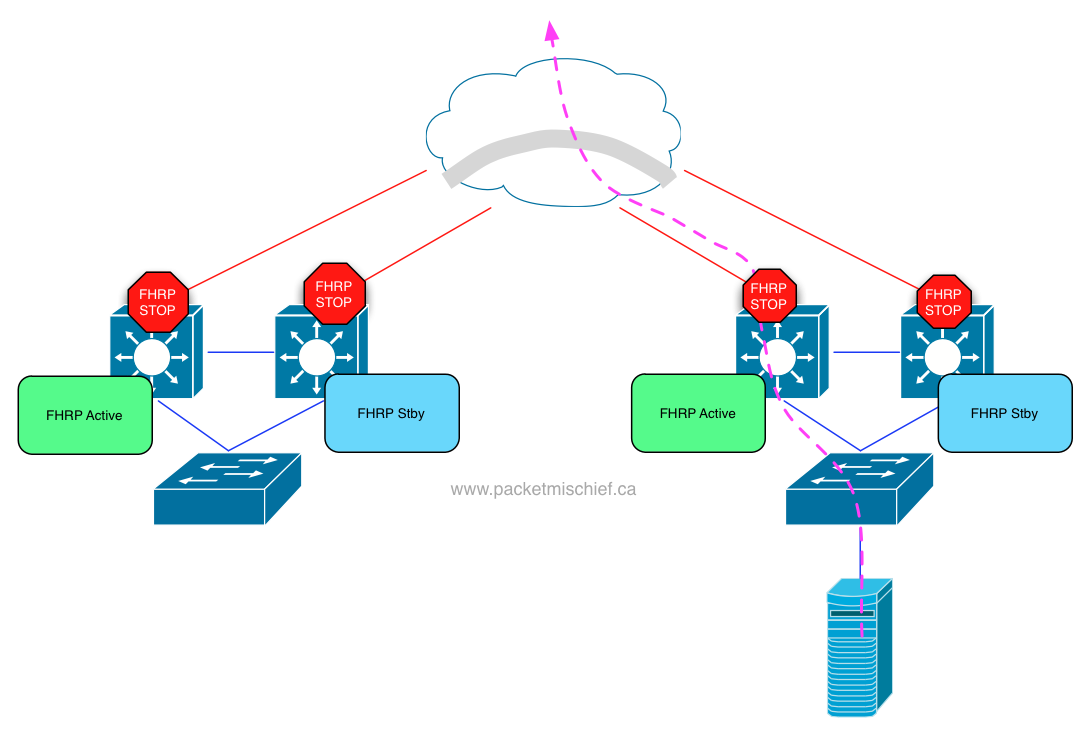
In the OTV article, I talk about how FHRP localization is part of OTV. As of this writing it's not automated — you have to create port-based ACLs to filter the FHRP hello packets on the DCI ports, but active/active gateways can be achieved (a CLI command to automate the PACLs is roadmapped).
The short explanation when it comes to FabricPath: today, there is no FHRP localization capability.
The longer answer is that this is a roadmap item. Cisco documentation calls this feature "Anycast FHRP" which indicates that it'll be possible to configure multiple switches within the fabric to act as gateways, all of them will be active, and ECMP will be used to spread flows amongst all of them.
Until Anycast FHRP arrives, there is a workaround and that is to configure the same HSRP group ID on both pairs of HSRP switches (thereby giving each pair the same VIP and VMAC) but configure a different authentication string. This will prevent the pair in Data Center Left from becoming HSRP peers with the pair in Data Center Right. When you do this, however, the pairs will still detect that their VIP is in use (by the other pair). This detection can be disabled in NX-OS with the "no ip arp gratuitous hsrp enable" command.
The reason FHRP localization is important from a DCI perspective is because, just like the OTV diagram above, it's inefficient to have inter-VLAN traffic traverse the DCI link to hit the server's gateway. It might be fine if the destination is a server that lives in Data Center Left, but what if that server is in DC Right? or is a client machine reachable via the WAN? It's more efficient to have the gateway local to the server routing the traffic so an intelligent forwarding decision can be made.
Multidestination Traffic⌗
Multidestination traffic refers to packets that are broadcast, unknown unicast, or multicast (so-called "BUM" traffic). Since FabricPath follows the rules of routing and not bridging, BUM traffic is not flooded on the network. Instead, it follows what's called a Multidestination Tree (MDT). A FabricPath MDT works very much like a traditional multicast tree where a root switch is elected/configured and loop-free branches out from the root are calculated.
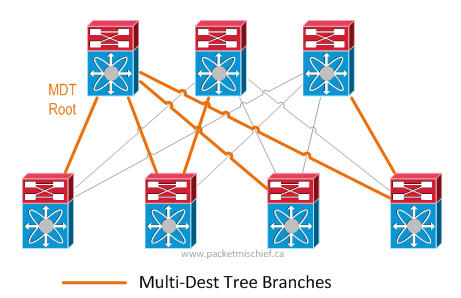
When BUM packets enter the fabric, they are sent along the tree. This is a very important part to understand: an FP switch that receives, say, a broadcast frame from an end station must send this frame on the tree which means that ultimately, that frame has to traverse the root switch in order to reach the whole network. Placement of the root switch becomes key in a DCI scenario. In an intra-DC scenario, it's less of an issue because the network topology is likely very symmetric — it's easier to place the root more in the "middle" of the network. In a DCI scenario, the root can only be at one site which means the other site(s) need to traverse the DCI for all BUM traffic**.**
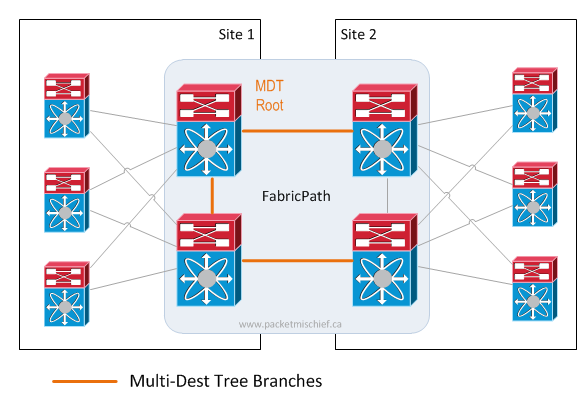
But wait, it can actually be worse. It's possible that switches in site(s) without a local root might have to forward all BUM traffic across the DCI link even for VLANs/hosts/receivers located in the same site as the ingress FabricPath switch. This happens when a Virtual Port Channel+ (vPC+) is configured between the FabricPath edge switches and a non-FP device (a classic ethernet switch, server, etc). With vPC+, the links between the FP switches and the non-FP device are both forwarding. So how do we prevent BUM traffic from ingressing on FP switch #1, being sent around through the fabric, hitting FP switch #2 and being sent back to the end station that originated the packet? vPC+ Designated Forwarder (DF). In a vPC+ pair, one of the switches is elected/configured as the DF. The DF is the only switch that will forward BUM traffic southbound on the vPC+ ports towards end stations.
So here's the scenario. BUM traffic enters the fabric (1). It is NOT the DF for the vPC where H2 is connected. The only place it can send this traffic is along the multidestination tree (2). In this scenario the BUM traffic leaves the data center (3), hits the MDT root (4), and then follows the tree back into the data center (5), hits the vPC+ member switch that is the DF for the vPC towards H2 (6) which then forwards it towards H2 (7).
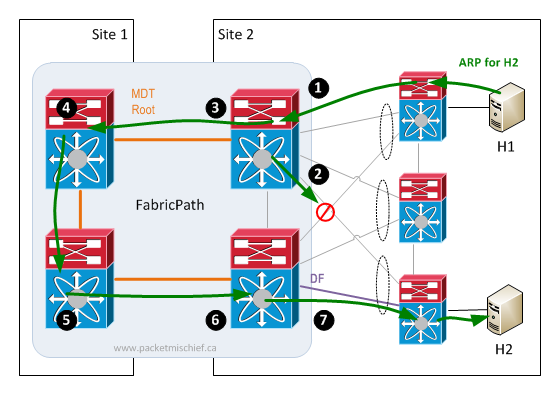
Because of the importance of the MDT root, its placement in the network should be considered carefully. This is especially true if there is a lot of multicast traffic within the data centers. Failure scenarios need to be analyzed as does bandwidth capacity feeding the root switch.
Closing Thoughts⌗
The three points above are some of the considerations for using FabricPath for DCI. The point about MDT root placement is probably the biggest one. As was told to me, a failure in the site that contains the root switch can ripple outward and affect traffic flows in other sites. This breaks the principle of failure domain isolation. On the other hand, FP provides Layer 3 semantics, fast convergence, and very high scalability which are all desirable qualities for DCI.
There certainly is a use case for using FabricPath as a DCI technology. People are doing this today. Is it better than another technology? It's all relative to the specific environment. As should be done with any technology: understand the requirements, understand the constraints and boundaries that need to be respected in the environment, and then line up the various technology options against these things. Use the right tool for the job.
Check out the other articles in my series on DCI and please feel free to leave a comment or question below.
Disclaimer: The opinions and information expressed in this blog article are my own and not necessarily those of Cisco Systems.