Five Features of Brocade VCS
Virtual Cluster Switching (VCS) is Brocade's brand of datacenter ethernet switching. VCS allows for the creation of a network fabric that's capable of converging storage and data traffic via standards-based datacenter bridging. It also solves the "Spanning Tree Protocol (STP) problem" by implementing a standards-based TRILL data plane paired with their own control plane in the form of Fabric Shortest Path First (FSPF). This data + control plane enable the "routing" of MAC addresses through the fabric, negates the need for STP, enables the use of all cabled links, and prevents traffic loops. VCS is only (currently) available on the VDX line of switches from Brocade.
In this post I'm going to outline five aspects of VCS that I found particularly interesting or unique. This is a companion article to an earlier one titled Five Functional Facts about FabricPath where I broke down five features of Cisco's fabric technology.
1. Switches Automatically Form a Fabric⌗
Brocade has built intelligence into their Network Operating System (NOS) on the VDX switches that enables two switches that are connected together to automatically turn those ports into fabric ports. This is accomplished by sending link layer discoveries and looking for an appropriate reply. The absence of a reply or a reply from a VCS switch that's configured with a different VCS fabric ID will cause the port to remain as an edge port and use classic ethernet forwarding rules. If a VCS switch is detected with the same fabric ID, control protocols are initialized which bring the new switch into the fabric by merging its configuration with that of the fabric. Topology information is then exchanged. In this way, the fabric automatically starts to form as VDX switches are connected together.
2. Equal Cost Multi-Path Uses Hop-Count as its Metric⌗
Within a VCS fabric, Equal Cost Multi-Path (ECMP) does not rely strictly on interface bandwidth for making a best path decision. An interface with a bandwidth of 10G or higher is assigned a fixed cost. This essentially turns the metric on 10G+ interfaces into a hop count metric.
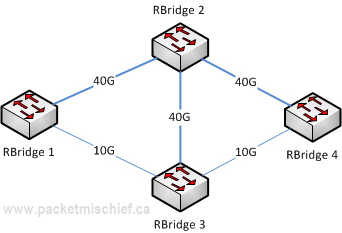
In the diagram above, RBridge 1 has two equal cost paths to RBridge 4. Both the 1/2/4 and 1/3/4 paths have all 10G and higher bandwidth links within them. This means the costs are all the same and that the decision essentially comes down to hop count. Since both paths have a hop count of (2), they are considered equal. Now if we were considering the path from RBridge 1 to RBridge 3, there are also two paths: 1/3 and 1/2/3. Again each path is made up of 10G and higher bandwidth links; however the 1/2 path has a hop count of (1) which makes it the only best path to reach RBridge 2.
Going back to the RBridge 1 to RBridge 4 example, now that we have two equal cost paths, how is traffic load balanced across them? By a typical hash function. NOS will feed the traditional 5-tuple plus the VLAN ID and source & destination MAC addresses into the hash function and put the frames on the resulting link. All frames from the same traffic flow will always follow the same path through the fabric guaranteeing in-order delivery.
[Update Sep 25, 2013] However, what NOS does above and beyond a simple hash is to take the aggregate bandwidth of the links into account. Since RBridge 1 has 40G of bandwidth on the path to RBridge 2 and only 10G on the path to RBridge 3, it will put 4 out of every 5 flows on the 40G link. In this way, NOS tries to ensure an appropriate utilization of each link that's proportionate to the link's bandwidth.
3. Virtual Link Aggregation Groups⌗
A Virtual Link Aggregation Group (vLAG) is a LAG (or Etherchannel, port-channel, etc) that extends from the VCS fabric to some non-VCS device. The interesting aspect of vLAGs is that they can terminate on multiple fabric ports that belong to different fabric switches.
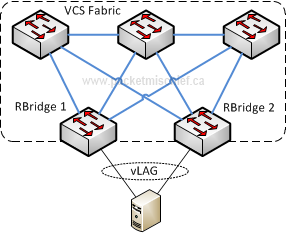
The server in this sample network is connected to the fabric via a vLAG. Note that RBridge 1 and RBridge 2 where the vLAG terminates are not directly cabled together. This is quite different from other multi-chassis link aggregation implementations. The ports where a vLAG terminates can be on any switch in the fabric, even ones that aren't connected directly together. There are some software limitations when it comes to vLAGs. As of this writing with NOS v2.1, there's a maximum of (4) switches that can participate in a single vLAG and a maximum of (32) ports in a vLAG where up to (16) of those ports can belong to a single switch.
The last thing I'll mention about vLAGs is that they support both classic ethernet and data center bridging. They do not, however, support Fibre Channel over Ethernet.
4. Hardware Based Link Aggregation Groups⌗
The VDX switches support a hardware based LAG which Brocade calls an Inter-Switch Link (ISL). Unlike vLAGs which are implemented in software (using standards-based Link Aggregation and Control Protocol (LACP)), ISLs are implemented in the switching ASIC. The ASIC takes care of load balancing traffic on the individual links on a per-packet basis. According to Brocade, this results in very high efficiency and near uniform utilization of the links. The first question that should come up at this point is, "how do ISLs maintain in-order frame delivery?" That's where Brocade's secret sauce comes in. ISLs are actually technology that Brocade has been using for many years in their Fibre Channel switches which means it's very mature and well tested. The switches are actually able to measure inter-link latencies and compensate for links that might be connected with longer cables than the others. They also insert shim headers into frames on the ISL that denote the proper order of the frames.
In keeping with the automatic formation of VCS fabrics, ISLs are automatically formed when two adjoining fabric switches are connected on multiple ports. Because the ISL is controlled by the ASIC, all ports in an ISL must be in the same hardware boundary called a "port group".
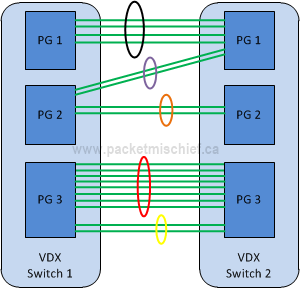
The two switches are able to determine which ports are connected together on which port groups and bring up the ISL automatically. For example, the purple and orange bundles are not connected to the same port group on switch 2. As a result the switches form two ISL links. The number of ports in a port group differs by switch model; however the maximum number of links in an ISL is always (8). Notice that there are (10) links between port group 3 on each switch. The switches form one ISL using (8) links and another using the remaining (2).
With respect to ECMP, each ISL is seen as a distinct link. In the diagram above, there would be (5) ECMP paths between the two switches (each ISL having a bandwidth of 10G or higher means they each have the same cost).
5. Automatic Migration of Port Profiles (AMPP) with VM-aware Network Automation⌗
AMPP is the feature in VDX switches that allows for control and visibility of virtual machines (VM) from the physical network. Without some sort of aid, the physical switch can't tell "who's who in the zoo". All the switch sees is a bunch of MACs on a port facing the host server. With AMPP, the network administrator builds a port profile which defines characteristics such as VLAN tag, QoS markings, and access control lists. This profile — which up until this point doesn't actually do anything, it just holds some specific configuration statements — is bound to a MAC address. The profile along with the binding is stored in the port profile database which is distributed to each switch throughout the fabric. Now when that MAC is seen on a port by any switch in the fabric, the port profile it's bound to is automatically applied to frames from that MAC.
Now, if you've thought this through you've probably realized that that's great and all, but it's very high touch. And yes, you're right. So enter the second part of the feature called VM-aware networking automation. This feature on the VDX line allows the fabric to talk directly with VMware's vCenter to automatically discover virtual machines and virtual distributed switches. NOS then automatically creates the necessary port profiles based on the port groups created in vCenter as well as any necessary VLANs. The MAC addresses belonging to VMs are bound to these port groups, again based on information from vCenter. The management burden is now greatly reduced as the switches will create the profiles based on whatever is configured in vCenter.
More Information⌗
I gleaned information for this post from these sources among others:
- Some info on how VCS fabrics form
- ISLs
- Brocade Virtual Symposium with techfieldday.com
- Brocade VCS Fabric Technical Architecture