DCI Series: Overlay Transport Virtualization
This is the third article in my series on Data Center Interconnection (DCI). In the first (Why is there a "Wrong Way" to Interconnect Data Centers?) I wrote about the risks associated with DCI when the method chosen is to stretch Layer 2 domains between the data centers.
In the second article (DCI: Why is Stretched Layer 2 Needed?) I wrote about why the need exists for stretching Layer 2 domains between sites and also touched on why it's such a common element in many DCI strategies.
In this article, I'm going to put all that soft stuff aside and get down into some technical methods for achieving a shared Layer 2 domain (ie, same IP subnet in both sites) while managing risk and putting a design in place that is resilient to Layer 2 failures. Namely, I'm going to talk about a protocol called Overlay Transport Virtualization (OTV).

An Overview of the Overlay⌗
OTV is referred to as an "overlay" protocol. As a network engineer, when you hear the word "overlay" you can pretty much translate that to "encapsulation". Take GRE or IPsec as an example. They both create an "overlay" network topology that lives "on top" of the physical (or "underlay") network. If you do a traceroute through a GRE tunnel, what topology do you see? You see the overlay/GRE topology. The underlay network provides transport between the overlay participants, but is otherwise insignificant. OTV works similarly where the underlay network is largely irrelevant and there is a new network topology running on top between the OTV endpoints.
Logical question now: if overlay is synonymous with encapsulation, what is encapsulated in an OTV packet?
Well, since OTV's purpose is to extend Layer 2 domains between sites, it's encapsulating Layer 2 frames. OTV itself is a routed protocol — it rides inside an IP packet — and within the OTV packet is the encapsulated Ethernet frame. When this inner Ethernet frame is decapsulated at the remote site as the OTV packet exits the overlay, the end host will have no idea that OTV even played a role in the transport of this packet. The inner Ethernet frame is not modified as it transits the overlay so from the point of view of the receiving end host, it looks as though the sender is on that same physical Layer 2 LAN.
One thing I haven't mentioned yet is where the OTV encap/decap is done. Remember, the end hosts know nothing about OTV so they do not require any configuration changes or extra software. OTV is done entirely in the network and would typically (but not always) be done at the gateway router for whichever VLAN(s) are being extended to the remote site.
Direct attachment to the Layer 2 domain/VLAN being extended is mandatory. The router doing the OTV encap needs to see the original Ethernet frames.
How is This Helpful?⌗
The key is in what I wrote earlier: OTV is a routed protocol. This means OTV packets can be sent across a Layer 3 interconnect. This is very important! Back in the first article in this series, I wrote about failure domains and how the size of a network failure domain is the same size as the Layer 2 domain. By building a routed interconnect between data centers, the failure domain is partitioned, isolating each data center from Layer 2 issues experienced in the other.
With OTV carrying the entire original Ethernet frame across the routed interconnect, to the end hosts it looks as though there is just one big Layer 2 domain.
A common Layer 2 network with isolated failure domains!
Is That All?⌗
I think the idea that OTV is a way of encapsulating Ethernet frames is pretty clear now. So the next logical question would be: If OTV encaps L2 over IP, why can't we just use something like Layer 2 Tunneling Protocol (L2TP)? Why invent something brand new?
There are actually lots of reasons why OTV was created. Some of those reasons have to do with features that aren't present in L2TP and others have to do with a larger vision (ever look closely at the headers for OTV, LISP and VXLAN? It's no mistake they are so similar). In general though it's because OTV was purpose built. Below I'm going to outline some of features in the OTV protocol that make it fit for DCI.
Unknown Unicast Suppression⌗
We all know that Ethernet switches flood frames that are destined to addresses which are not known to the switch. By contrast, OTV adopts the behavior of IP routers where if the address is not known (ie, the address is not present in the forwarding table) the packet is simply dropped. This behavior is far more scalable and eliminates the blasting of packets throughout the network as a way of packet delivery.
In the case of OTV, this creates an interesting situation where the OTV control plane must advertise newly learned addresses (MACs) to its neighbors before traffic can be passed from those neighbor sites to the local end host. Again, these semantics mimic that of routing protocols and ensure a more stable, scalable network.
Spanning Tree Domain Isolation⌗
OK, let's think this through for a minute. With OTV we've got our data centers separated by a Layer 3 interconnect, yet OTV is carrying Layer 2 frames between the data centers. Does that mean STP BPDUs are passing between the two sites?
It's actually a trick question. OTV has native support for STP isolation whereby the router performing the OTV encapsulation will recognize STP BPDUs and prevent them from being delivered across the overlay. This completes the partitioning of the Layer 2 domain between the sites. The data plane is isolated by way of the Layer 3 interconnect and now the control plane is isolated thanks to this native optimization in OTV.
First Hop Redundancy Protocol Isolation⌗
In addition to STP BPDUs floating around the networks at either data center, there are also HSRP or VRRP packets. Since the Layer 2 domain is stretched, what happens to these protocols? Well, all of the HSRP/VRRP speakers are going to hear each other, an election will happen and one of the speakers will be elected the leader and own the VMAC/VIP. That works fine for hosts in the same site as the leader, but what about hosts in a remote site?
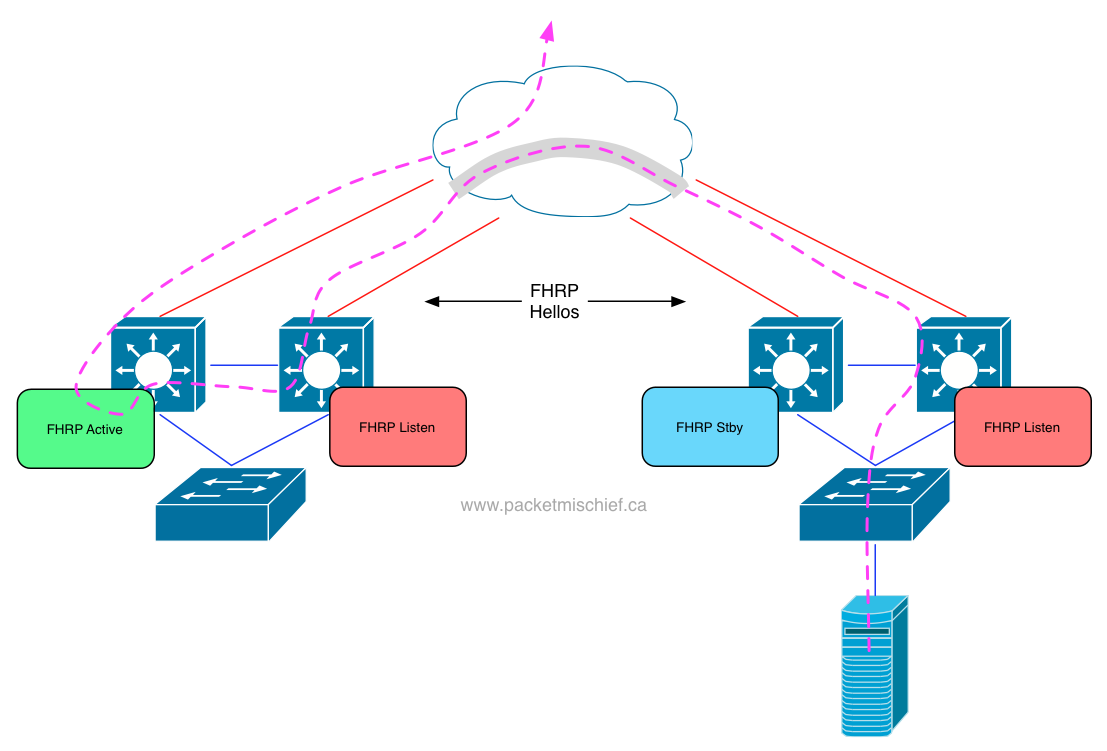
Those hosts will have to transit the overlay in order to reach their default gateway. That's not exactly efficient.
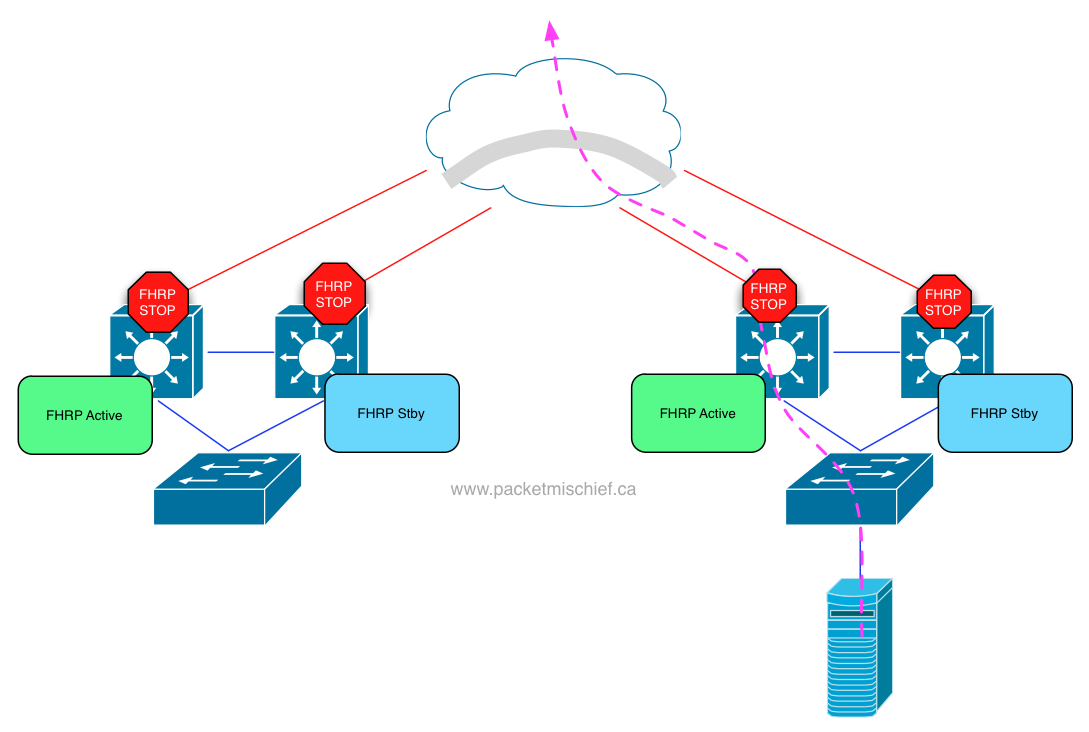
As of this writing, OTV doesn't yet have a native optimization for filtering HSRP/VRRP packets as it does for STP BPDUs. It is coming in the future. Today, manual ACLs must be created to block the HSRP/VRRP packets from crossing the overlay. With that in place, each site will have an active FHRP router leading to more efficient northbound traffic flow.
Others⌗
Those are my top three features that I believe make OTV fit for purpose. There are other interesting aspects of the protocol but they start to get way into the weeds and require explaining a lot more about how the protocol works and that's not what this post is about. To get into the nitty gritty of OTV, check out the protocol draft at the IETF.
Summary⌗
As I've emphasized over and over in this series, bridging a Layer 2 domain between sites is just asking for trouble. However network engineers have to address the requirement (the occasional requirement, not the do-it-all-the-time requirement) for having the same Layer 2 domain in more than one location. OTV enables a sane, resilient network design while at the same time meeting the requirements of application and platform operators when it comes to stretched Layer 2.
Stay tuned for more. The next post in this series will talk about additional methods for enabling resilient data center interconnection.
Disclaimer: The opinions and information expressed in this blog article are my own and not necessarily those of Cisco Systems.