Tools for TE with EIGRP
In response to my article about what would cause a directly connected route to be overridden, Matt Love (@showflogi) made a good observation:
Good stuff - LPM rule can be a useful tool if you want to manipulate paths without mucking with metrics, esp if using multiple protocols
— Matt Love (@thatmattlove) July 13, 2017
What Matt is saying is that longest prefix match (LPM) is a mechanism that can be used to steer traffic around the network in order to meet a technical or business need. This type of traffic steering is called traffic engineering (TE).
LPM refers to how route lookups work on a Layer 3 device: the longest, most-specific match is always chosen. Like I explained in the prior post, if the routing table contains 10.10.10.0/24 and 10.10.10.64/26, the latter route will be used to forward traffic to 10.10.10.100 (as an example) because a /26 is longer (ie, has a longer prefix length) and is therefore more specific. We can use this behavior to direct traffic towards 10.10.10.100 over a specific interface or via a specific path (ie, a path with lower latency, better QoS, or more bandwidth) by ensuring the /26 is advertised over that path and the /24 is advertised over the other, less preferred path(s).
"But hold up!", you say. Why can't we just fiddle with metrics and assign the 10.10.10.64/26 route a better metric on the preferred path?
The answer is because when using an interior gateway protocol, metrics are derived from interfaces not from prefixes.
Let's go through this in detail, first by looking at OSPF as our example IGP, then at BGP (which behaves the opposite to IGPs in this regard) and finally at EIGRP as our example of an IGP that behaves like the other IGPs but has more flexibility.
Where Does OSPF Get Its Metric?⌗
As a refresher, in the Cisco world, the OSPF metric is calculated with the formula:
metric = reference_bw / interface_bw
This pretty much gives away the answer to the question since the word "interface" is right there in the formula :-). It's an interface property that is used to calculate the metric. Consider the example network below:
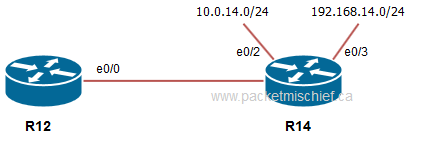
R14 is advertising the 10.0.14.0/24 network into OSPF. It's the source of this prefix in the OSPF domain. If we inspect the OSPF database on R14, we can see it stores a metric of 10.
R14#show ip ospf database router 14.14.14.14
OSPF Router with ID (14.14.14.14) (Process ID 1)
Router Link States (Area 0)
[...snip...]
Link connected to: a Stub Network
(Link ID) Network/subnet number: 10.0.14.0
(Link Data) Network Mask: 255.255.255.0
Number of MTID metrics: 0
TOS 0 Metrics: 10
This is calculated by the above formula:
r14_metric = reference_bw / interface_bw
r14_metric = 10^8 / 10,000,000 = 10
10^8 is the default OSPF reference bandwidth in Cisco IOS.
If we move one hop back, to R12, and look in the OSPF database, we see a metric of 14.
R12#show ip ospf database router 14.14.14.14
OSPF Router with ID (12.12.12.12) (Process ID 1)
Router Link States (Area 0)
[...snip...]
Link connected to: a Stub Network
(Link ID) Network/subnet number: 10.0.14.0
(Link Data) Network Mask: 255.255.255.0
Number of MTID metrics: 0
TOS 0 Metrics: 10
R12#show ip ospf database router 12.12.12.12
OSPF Router with ID (12.12.12.12) (Process ID 1)
Router Link States (Area 0)
[...snip...]
Link connected to: a Transit Network
(Link ID) Designated Router address: 123.1.1.14
(Link Data) Router Interface address: 123.1.1.12
Number of MTID metrics: 0
TOS 0 Metrics: 4
This is calculated by taking the metric that R14 advertises for the route and adding R12's metric to reach R14. R12's metric is:
r12_metric = 10^8 / 25,000,000 = 4 (the cost on the 123.1.1.14 transit network)
Final metric: 10 (from R14) + 4 (local metric) = 14
(R12's e0/0 interface is running at 25Mb/s)
R12#show ip route 10.0.14.0
Routing entry for 10.0.14.0/24
Known via "ospf 1", distance 110, metric 14, type intra area
[...snip...]
Now let's look at a different network that R14 is advertising. I'm just going to jump right to looking at it on R12 rather than repeat all the above steps:
R12#show ip ospf database router 14.14.14.14
OSPF Router with ID (12.12.12.12) (Process ID 1)
Router Link States (Area 0)
[...snip...]
Link connected to: a Stub Network
(Link ID) Network/subnet number: 192.168.14.0
(Link Data) Network Mask: 255.255.255.0
Number of MTID metrics: 0
TOS 0 Metrics: 10
R12#show ip route 192.168.14.0
Routing entry for 192.168.14.0/24
Known via "ospf 1", distance 110, metric 14, type intra area
[...snip...]
Notice the metric is the same for both networks. This brings me to the point: routes learned along the same path will have the same metric treatment. The metric is derived by properties of the interfaces along the path so therefore all routes learned on an interface will have the same metric increase.
If the properties of the interface(s) on the path are modified in order to make it more or less preferred, that modification affects all routes learned on the interface(s).
R12#conf t
R12(config)#int e0/0
R12(config-if)#bandwidth 10000
R12(config-if)#^Z
R12#show ip route 10.0.14.0 | inc metric
Known via "ospf 1", distance 110, metric 20, type intra area
Route metric is 20, traffic share count is 1
R12#show ip route 192.168.14.0 | inc metric
Known via "ospf 1", distance 110, metric 20, type intra area
Route metric is 20, traffic share count is 1
Where Does BGP Get Its Metric?⌗
BGP works the opposite way of an IGP. BGP assigns attributes to the route and uses them to determine the best path. BGP does not look at interfaces.
This is what makes BGP so powerful for internet service providers. They can use BGP to enact complex policies about where traffic should go on its way in or out of their networks. For example, an ISP can use BGP to direct all traffic destined to Netflix to exit the network at peering point "A" while traffic going to Amazon Web Services should exit peering point "B". This is done by manipulating attributes on the Netflix/AWS routes themselves to make them more attractive in certain locations of the network and maybe less attractive in others. This can be done-and still works just fine-even if the Netflix and AWS traffic cross the same interfaces at certain points in the ISP network.
What Makes EIGRP Special?⌗
EIGRP works like OSPF in that it derives the metric from interface properties (bandwidth and delay, by default). If we take our sample network again and reconfigure it to run EIGRP, we can see that R14 has calculated a metric for the two networks of 131072000 which is based on the interface bandwidth of 10,000kb/s and delay of 1000us (or 1,000,000,000ps).
R14#show ip eigrp topology 10.0.14.0 255.255.255.0
EIGRP-IPv4 VR(ROCKS) Topology Entry for AS(65201)/ID(10.1.14.14) for 10.0.14.0/24
State is Passive, Query origin flag is 1, 1 Successor(s), FD is 131072000
Descriptor Blocks:
0.0.0.0 (Ethernet0/2), from Connected, Send flag is 0x0
Composite metric is (131072000/0), route is Internal
Vector metric:
Minimum bandwidth is 10000 Kbit
Total delay is 1000000000 picoseconds
Reliability is 255/255
Load is 1/255
Minimum MTU is 1500
Hop count is 0
Originating router is 10.1.14.14
R14#show ip eigrp topology 192.168.14.0
EIGRP-IPv4 VR(ROCKS) Topology Entry for AS(65201)/ID(10.1.14.14) for 192.168.14.0/24
State is Passive, Query origin flag is 1, 1 Successor(s), FD is 131072000
Descriptor Blocks:
0.0.0.0 (Ethernet0/3), from Connected, Send flag is 0x0
Composite metric is (131072000/0), route is Internal
Vector metric:
Minimum bandwidth is 10000 Kbit
Total delay is 1000000000 picoseconds
Reliability is 255/255
Load is 1/255
Minimum MTU is 1500
Hop count is 0
Originating router is 10.1.14.14
Similarly, R12 has calculated its own metric based on what is received from R14 plus its own interface bandwidth and delay:
R12#show ip eigrp topology 10.0.14.0 255.255.255.0
EIGRP-IPv4 VR(ROCKS) Topology Entry for AS(65201)/ID(10.1.12.12) for 10.0.14.0/24
State is Passive, Query origin flag is 1, 1 Successor(s), FD is 196608000, RIB is 1536000
Descriptor Blocks:
123.1.1.14 (Ethernet0/1), from 123.1.1.14, Send flag is 0x0
Composite metric is (196608000/131072000), route is Internal
Vector metric:
Minimum bandwidth is 10000 Kbit
Total delay is 2000000000 picoseconds
Reliability is 255/255
Load is 1/255
Minimum MTU is 1400
Hop count is 1
Originating router is 10.1.14.14
R12#show ip eigrp topology 192.168.14.0
EIGRP-IPv4 VR(ROCKS) Topology Entry for AS(65201)/ID(10.1.12.12) for 192.168.14.0/24
State is Passive, Query origin flag is 1, 1 Successor(s), FD is 196608000, RIB is 1536000
Descriptor Blocks:
123.1.1.14 (Ethernet0/1), from 123.1.1.14, Send flag is 0x0
Composite metric is (196608000/131072000), route is Internal
Vector metric:
Minimum bandwidth is 10000 Kbit
Total delay is 2000000000 picoseconds
Reliability is 255/255
Load is 1/255
Minimum MTU is 1400
Hop count is 1
Originating router is 10.1.14.14
Like OSPF, if we manipulate bandwidth and/or delay on an interface, we change the metric for all routes learned on that interface.
That's a small white lie. If you change the interface bandwidth, you might cause a change in EIGRP metric, but only if the bandwidth you're changing from or to was/is the lowest bandwidth along the path. EIGRP only cares about the lowest bandwidth, not the bandwidth of each interface. PS, it's also not advisable to modify the bandwidth; tweak the delay if you need to manipulate an EIGRP interface metric.
Here's where EIGRP is different though. Because it has distance vector-like properties, we're actually free to modify the metric anywhere in the network. And the EIGRP Scientists (which I very respectfully refer to the current and former developers as) have given us the knobs to manipulate the metric of individual routes as they enter the EIGRP topology table.
There are two methods that can be used to do this
- Offset lists
- Enhanced route-maps
An offset list defines a static value (an offset) that is added or subtracted to/from the metrics of a route or a set of routes. This allows taking preference or giving preference, respectively, from/to a route on a particular interface.
R12#show run | sec OFFSET_ROUTES
ip access-list standard OFFSET_ROUTES
permit 10.0.14.0
R12#show run | sec eigrp
router eigrp ROCKS
address-family ipv4 unicast autonomous-system 65201
topology base
offset-list OFFSET_ROUTES in 42 Ethernet0/1
[...snip...]
R12#show ip eigrp topology 10.0.14.0 255.255.255.0 | inc Composite
Composite metric is (196608042/131072042), route is Internal
Enhanced route-map is the name of the feature that was added to Cisco IOS that allows a route-map to manipulate the EIGRP component metric values on a matching route. The route-map can match the interface the route is learned on and then modify the metric values up or down.
R12#show run | sec access-list
ip access-list standard ENH_ROUTEMAP_ROUTES
permit 192.168.14.0
R12#show run | sec route-map EIGRP_IN
route-map EIGRP_IN permit 5
match ip address ENH_ROUTEMAP_ROUTES
match interface Ethernet0/1
set metric 10000 12345 255 1 1400
R12#show run | s eigrp
router eigrp ROCKS
address-family ipv4 unicast autonomous-system 65201
topology base
distribute-list route-map EIGRP_IN in
[...snip...]
R12#show ip eigrp topology 192.168.14.0 | inc Composite|delay
Composite metric is (8155955200/131072000), route is Internal
Total delay is 123450000000 picoseconds
Summary⌗
In a nutshell, here's what this all means:
- IGPs calculate their metrics by looking at the interfaces along the path and using one or more properties on the interface to derive a metric value
- All routes learned on the same interface will get the same metric treatment (ie, their metric will either be set or increased by the same amount)
- Changing an interface's properties (and the resulting IGP metric) will change the metric for all routes learned on that interface
- BGP behaves the opposite to IGPs and doesn't look at interfaces at all
- BGP is made for enacting complex forwarding policies and allows assigning attributes to individual routes to influence path decisions with per-route granularity
- EIGRP follows the IGP behavior but because of its nature it allows manipulation of metrics on individual routes
- With EIGRP it's possible to do per-route traffic engineering
Going back to Matt's comment about using LPM for path selection, you can see now why that's important when using an IGP. LPM offers a method for doing granular traffic engineering that works even if the IGP in use doesn't allow manipulation of metric information on a per-route basis. With LPM, you can perform traffic engineering with specific routes without applying drastic metric changes to all routes learned on an interface.
Disclaimer: The opinions and information expressed in this blog article are my own and not necessarily those of Cisco Systems.