3 Ways to Fail at Logging with Flask

For the benefit of readers who haven't worked with Flask or don't know what Flask is, it's a so-called microframework for writing web-based applications in Python. Basically, the framework takes care of all the obvious tasks that are needed to run a web app. Things like talking HTTP to clients, routing incoming requests to the appropriate handler in the app, and formatting output to send back to the client in response to their request. When you use a framework like this, you as the developer can concentrate a lot more on the application logic and worry a lot less about hooking the app into the web.
As you may have guessed from the title of this post, one of the other tasks that Flask manages is logging within the application. For example, if you want to emit a log message when a user logs in or when they upload a new photo, Flask provides a simple interface to generate those log messages.
Flask has a large community of active users built around it and as a result, there's tons of best practice information out there on scaling, talking to a database, and even whole tutorials on how to build full applications. But it's been my experience that there is very little information devoted to the topic of logging. Granted logging isn't very fun and does nothing to get your app to market quicker or increase user counts, but it is really important if you want to get any sort of feedback from the app about what it's doing during normal operation or what exactly happened if something goes wrong.
In this post, I'll look very briefly at how logging works in Flask and then examine three common methods used to record log files within Flask and how each of them can shoot you in the foot. I'll close by offering some recommendations that should keep you on safe ground.
How Logging Works in Flask⌗
Logging in Flask is actually very straightforward. Your Flask application object will be instantiated with a logger property which returns a regular Python Logger object from the standard logging module. Emitting a log entry is as simple as calling one of the helper methods (info(), warn(), error(), etc) which will emit an entry at the specified severity.
from flask import Flask
app = Flask(__name__)
app.logger.info('This is a log message!')
By default, log messages are written to stderr which means they are output on the terminal when running the built-in development web server or in production would need to be captured by your WSGI server and stored somewhere.
Since Flask uses Python's standard logging module as the basis for its logging subsystem, there are plenty of ways in which we can control logging in Flask, including where messages are written to. The three output methods I'm going to explore-which I would argue are the three most common methods shared around the Flask community- are:
- Rotating log file
- Timed rotating log file
- Watched log file
Logging to a Rotating Log File⌗
A rotating log file is simply a file to which log entries are written that will subsequently be rotated out at some point in the future based on some criteria that is established at the time the log file is first opened. This is very, very similar to the behavior of the newsyslogd(8) daemon on BSD operating systems or logrotate(8) on Ubuntu and friends except that here the application itself will do the file rotation and not an external process. This is a key concept that will come up again later. A rotation will occur when the current log file approaches a defined maximum size at which point the Flask application will rename the current file to <file>.1, create a new <file> and then start logging to that new file.
Some sample code might look like this:
import loggingimport logging.handlers
from flask import Flask
app = Flask(__name__)
handler = logging.handlers.RotatingFileHandler(
'app.log',
maxBytes=1024 * 1024)
handler.setLevel(logging.INFO)
app.logger.addHandler(handler)
app.logger.info('This message goes to stderr and app.log!')
This code instantiates a new instance of the handler type RotatingFileHandler, defines the log file name (app.log) and the max size of the file (1MB). It then sets the minimum severity level that the handler will acknowledge (INFO) and then binds the handler to the logger object (note that the way the code is written, any existing handlers are not replaced which is why the log message also goes to the default stderr destination).
On its own, this code is just fine and will work well. Let's segue for a minute and examine how this becomes problematic.
We need to first build a mental model to describe how a Flask app actually runs in production. In order for the application to be accessible to a web browser, a web server process must sit somewhat "in front" of the application processes. In the Python world, it's very common for the web server and application processes to talk via a standard interface called the Web Server Gateway Interface (WSGI). The web/WSGI server is responsible for launching the application processes and what it will typically do is launch multiple instances of the app process so that multiple incoming requests from users can be serviced at the same time. These app processes are often called workers because they do the actual work that the application was designed to do. Here's what this model looks like:
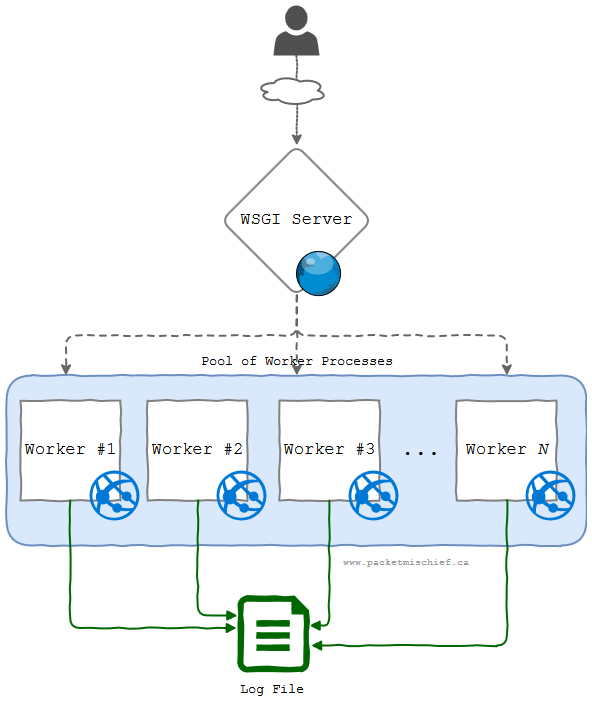
What's important to realize here is that each worker process is literally that: a process running on the server. And by definition, each process has its own virtual memory space and file handles. There is nothing natively shared between the workers; no synchronization or even awareness that any other worker exists.
With that in mind, if we think about each worker writing to a log file, it's important to keep this in context that each worker thinks it's the only worker running and that it "owns" the log file.
Now let's jump back to our analysis of the rotating log file. I've written a very simple Python script to bench test all three log file handler types mentioned in the introductory section. This script is not using Flask, however it does use the same logging module and is a suitable stand-in for testing logging behavior.
The script and resulting outputs can be found on my GitHub account at https://github.com/knightjoel/flask_logtest.
When the script is run, it opens the log file using the handler that is specified as a command line option (-t) and then every second it writes its process id (PID), the word "Hello" and an incrementing sequence number to the log. By running multiple instances of the script, this will simulate the worker processes.
When the script is run with the optional -r option, it will do as described above but before writing its first log entry, it will manually request that the logging handler rotate the log file. This is to simulate the log file reaching its max size and being rotated by a worker.
Here are the results of the test with a rotating log file:
Start the workers:
% for i in 1 2 3; do python test.py -t rotating & done
[2] 69477
[3] 36909
[4] 95433
Tail the log file. Note each PID is writing a log entry each second along with its sequence number:
2017-10-23 18:34:28,430 pid/36909 Hello 36
2017-10-23 18:34:28,460 pid/95433 Hello 36
2017-10-23 18:34:28,460 pid/69477 Hello 36
2017-10-23 18:34:29,450 pid/36909 Hello 37
2017-10-23 18:34:29,480 pid/69477 Hello 37
2017-10-23 18:34:29,480 pid/95433 Hello 37
Now launch a 4th worker and instruct it to rotate the log:
% python test.py -t rotating -r
Rolling over <RotatingFileHandler /home/joel/flask/logtest/rotating/logtest.log (INFO)> now (2017-10-23 18:34:31.076268)
Logging to <RotatingFileHandler /home/joel/flask/logtest/rotating/logtest.log (INFO)> now
Now tail the log file again and check the results:
2017-10-23 18:34:30,460 pid/36909 Hello 38
2017-10-23 18:34:30,490 pid/69477 Hello 38
2017-10-23 18:34:30,490 pid/95433 Hello 38
tail: logtest.log has been replaced, reopening.
2017-10-23 18:34:31,076 pid/28830 Hello 0
2017-10-23 18:34:32,080 pid/28830 Hello 1
2017-10-23 18:34:33,090 pid/28830 Hello 2
2017-10-23 18:34:34,100 pid/28830 Hello 3
Here we see a problem. The log file was rotated at 18:34:31.076268 after which only the 4th worker process is writing to the log; the log entries from the first three workers are missing. If we inspect the rotated log file, logfile.log.1, we see that those workers are still logging to the old file:
2017-10-23 18:34:29,450 pid/36909 Hello 37
2017-10-23 18:34:29,480 pid/69477 Hello 37
2017-10-23 18:34:29,480 pid/95433 Hello 37
2017-10-23 18:34:30,460 pid/36909 Hello 38
2017-10-23 18:34:30,490 pid/69477 Hello 38
2017-10-23 18:34:30,490 pid/95433 Hello 38
2017-10-23 18:34:31,470 pid/36909 Hello 39
2017-10-23 18:34:31,500 pid/69477 Hello 39
2017-10-23 18:34:31,500 pid/95433 Hello 39
The reason this happens is because each worker has its own file handle open for the log file. The one worker that decides its time to rotate the file will first close the log file, rotate the file, then open a new file with the original name. The rest of the workers don't do this; they continue logging to the file they opened when they first started and since that file has been renamed, log entries end up in a file that isn't the one that we expect.
Conclusions for a rotating log file:
- There is a race condition present where the one worker that decides it's time to rotate the file will continue to log as expected.
- The workers that lose the race will write their log entries in a rotated file which is not the location that's expected.
- Rotated-out log files will continue to grow as workers write more log entries.
- At some point, the workers that are writing to a rotated-out file will decide it's time to rotate that file and then the problem will just start to compound.
Logging to a Timed Rotating Log File⌗
A timed rotating log file is a lot like a rotating log file however the rotation is scheduled to happen on a certain time interval. For example, you can roll the log "every Monday at midnight" or "every hour on the hour", that sort of thing. My test script is configured to rotate the log every 60 seconds. Let's run it.
Run the workers:
% for i in 1 2 3; do python test.py -t timed & done
[2] 11866
[3] 78280
[4] 98040
Tail the log file:
2017-10-24 14:33:21,683 pid/78280 Hello 0
2017-10-24 14:33:21,695 pid/11866 Hello 0
2017-10-24 14:33:21,697 pid/98040 Hello 0
2017-10-24 14:33:22,688 pid/78280 Hello 1
2017-10-24 14:33:22,698 pid/98040 Hello 1
2017-10-24 14:33:22,698 pid/11866 Hello 1
2017-10-24 14:33:23,698 pid/78280 Hello 2
2017-10-24 14:33:23,708 pid/98040 Hello 2
2017-10-24 14:33:23,708 pid/11866 Hello 2
Now just wait for a rotation event (no manual rotation in this test)...
2017-10-24 14:34:05,189 pid/78280 Hello 43
2017-10-24 14:34:05,199 pid/11866 Hello 43
2017-10-24 14:34:05,199 pid/98040 Hello 43
2017-10-24 14:34:06,209 pid/98040 Hello 44
2017-10-24 14:34:06,209 pid/11866 Hello 44
tail: timed/logtest.log has been replaced, reopening.
2017-10-24 14:34:06,199 pid/78280 Hello 44
2017-10-24 14:34:07,209 pid/78280 Hello 45
2017-10-24 14:34:08,219 pid/78280 Hello 46
2017-10-24 14:34:09,244 pid/78280 Hello 47
Looks like PID 78280 rotated the file and as expected, continues to write log messages to the original file. The other workers are presumably writing to the rotated file. Before I can check though, the other workers each initiate their own rotation:
2017-10-24 14:34:20,359 pid/78280 Hello 58
2017-10-24 14:34:21,369 pid/78280 Hello 59
tail: timed/logtest.log has been replaced, reopening.
2017-10-24 14:34:21,379 pid/11866 Hello 59
2017-10-24 14:34:22,399 pid/11866 Hello 60
tail: timed/logtest.log has been replaced, reopening.
2017-10-24 14:34:22,399 pid/98040 Hello 60
2017-10-24 14:34:23,410 pid/98040 Hello 61
So now the file has been rotated three times within the same minute. Not the desired behavior. It's actually a little worse than that though: log messages are being lost. First, this was output on the terminal where I launched the workers:
% --- Logging error ---
Traceback (most recent call last):
File "/usr/local/lib/python3.6/logging/handlers.py", line 72, in emit
self.doRollover()
File "/usr/local/lib/python3.6/logging/handlers.py", line 395, in doRollover
os.remove(dfn)
FileNotFoundError: [Errno 2] No such file or directory: '/home/joel/flask/logtest/timed/logtest.log.2
017-10-24_14-33'
Call stack:
File "test.py", line 60, in <module>
main()
File "test.py", line 34, in main
logger.info('Hello {}'.format(seq))
Message: 'Hello 59'
Arguments: ()
One of the workers-most likely 98040-was unable to write a message to its log file. That message ("Hello 59") is lost! Buuut, it's worse than that too. I let the test run for a total of 2 minutes during which time there were six rotations. How many log files would you expect to see on the disk? Probably 7? Six rotated files and the active file?
% ls -l
total 8
-rw-r--r-- 1 joel joel 262 Oct 24 14:35 logtest.log
-rw-r--r-- 1 joel joel 2555 Oct 24 14:35 logtest.log.2017-10-24_14-33
-rw-r--r-- 1 joel joel 394 Oct 24 14:35 logtest.log.2017-10-24_14-34
There are only 3 files on disk. And if we check for some specific log entries, we find that they are not in any of the files:
% grep -c "Hello 0" *
logtest.log:0
logtest.log.2017-10-24_14-33:0
logtest.log.2017-10-24_14-34:0
Conclusions for timed rotating log file:
- It's very clear there is a race condition between the workers: they will each attempt to rotate the file on their own independent schedule.
- The workers that lose a race will write their log entries in a rotated file which is not the location that's expected.
- Rotated-out log files will continue to grow as workers write more log entries.
- When one of the losing workers goes to rotate the file, it ends up rotating an already rotated-out file which causes the chaos to compound.
- As more workers rotate their log file, log messages start to land in more and more confusing places and eventually log messages are lost completely either because log files are overwritten or a file that's being used by one worker is deleted by another.
Logging to a Watched Rotating Log File⌗
A watched rotating log file is a lot like a rotating log file except the actual rotation of the file is the responsibility of a third-party such as newsyslogd(8) or logrotate(8). When a worker notices the log file has been rotated, it will close its existing file handle and open the log file again in order to ensure it's writing to the new, non-rotated file.
For this test, I will run the workers and then manually "mv" the log file out of the way.
Workers:
% for i in 1 2 3; do python test.py -t watched & done
[2] 96616
[3] 72481
[4] 48399
Log file:
2017-10-24 15:02:34,291 pid/96616 Hello 0
2017-10-24 15:02:34,327 pid/48399 Hello 0
2017-10-24 15:02:34,327 pid/72481 Hello 0
2017-10-24 15:02:35,298 pid/96616 Hello 1
2017-10-24 15:02:35,328 pid/72481 Hello 1
2017-10-24 15:02:35,328 pid/48399 Hello 1
2017-10-24 15:02:36,318 pid/96616 Hello 2
2017-10-24 15:02:36,348 pid/72481 Hello 2
2017-10-24 15:02:36,348 pid/48399 Hello 2
Manually rotate the log file by moving it out of the way:
% mv logtest.log logtest.log.1
Inspect log file again:
2017-10-24 15:02:51,549 pid/96616 Hello 17
2017-10-24 15:02:51,599 pid/48399 Hello 17
2017-10-24 15:02:51,599 pid/72481 Hello 17
tail: watched/logtest.log has been replaced, reopening.
2017-10-24 15:02:52,569 pid/96616 Hello 18
2017-10-24 15:02:52,619 pid/48399 Hello 18
2017-10-24 15:02:52,619 pid/72481 Hello 18
2017-10-24 15:02:53,579 pid/96616 Hello 19
2017-10-24 15:02:53,629 pid/48399 Hello 19
2017-10-24 15:02:53,629 pid/72481 Hello 19
2017-10-24 15:02:54,589 pid/96616 Hello 20
2017-10-24 15:02:54,639 pid/48399 Hello 20
2017-10-24 15:02:54,639 pid/72481 Hello 20
Interesting results: Each worker picked up the fact that the file had been rotated and did the right thing by closing the rotated file and opening the new log file.
Conclusions for watched rotating file handle:
- No log messages were written to a rotated-out file; all log messages were written to the main log file which conforms to expected behavior.
- No log messages were lost; each worker was able to write all of their messages to disk.
- While it did not show up in this test, there is still a race condition here: there is a tiny window of time between when a worker does the rotation and when it writes its next log message during which the file may rotate out before the log message is written. This would result in behavior very similar to the base rotating file handler tests where log messages would be written to a rotated-out file.
Summary⌗
- It is not safe to log to a common file in a software architecture that uses a number of pre-forked worker processes as is very common in Flask deployments.
- In the best case log entries will just be misplaced.
- In the worst case log entries will be lost.
- The watched rotating log file has the smallest window for error while the timed rotating log file has the largest window for error.
Recommendations⌗
I do not consider myself experienced enough to be giving advice on Python or Flask, but based on these little tests and some critical thinking, this is the approach I plan to take on any future projects with Flask (or any other software stack that uses a pre-forked worker model):
- I will forgo logging to files altogether and instead have log messages go to syslog. I'll use the native OS tools for capturing and managing log messages coming from the app rather than trying to build robust log handling into the app itself. As an added bonus, this design will make it trivial to get the log messages off the box and into either a central log repo or maybe a third-party tool such as Sentry.
- If for some reason syslog is not an option, I will opt for the watched rotating log file since it has a very narrow window for error. I'll use the native OS tools for rotating the log file. If the consequences of losing even a single log message are too great, then syslog will have to be made available so that option #1 can be used.
References⌗
- Flask quickstart on logging
- Python logging documentation
- Python logging.handlers documentation
- Python logging.handlers module source code
- Flask logging module source code