Why I Enthusiastically Switched from Cacti to Zabbix for System Monitoring
Cacti is a "complete network graphing solution" according to their website. It has also been a thorn in my side for a long time.
See what I did there? Thorn... because it's a cactus... never mind.
When Cacti is in a steady state-when I could get it to a steady state-it was good. Not great, because there was a lot of effort to get it into what I consider "steady state", but good. The rest of the time... thorny.
There are five major things that have driven me up the wall. In no particular order:
Round Robin Database (RRD) sucks⌗
The concept behind RRD is cool: a fixed-size, circular database (oldest data overwritten by the newest data) makes good sense for the type of data that a network graphing solution collects. In practice, using RRD means:
- Another software dependency that needs to be updated, patched, and integrated in the Cacti ecosystem
- Manually managing all of the RRD files that are generated for all of the data sources you're collecting. RRD stores its data in individual files on the file system, you see, and the more data sources you collect with Cacti, the more RRD files you have to store and manage.
- Your data is fragmented. The data you've collected from the network-and only that data-is in the RRD files. The information about the devices you're collecting from (IP address, SNMP community string, when the poller last ran) are all stored in a separate, relational database (which is almost always MySQL). To back up your Cacti install, you need to backup both groups of data. Using different tools. And of course they have different restore methods. And you're almost guaranteed different restore points.
Using SNMP for data collection is tedious⌗
And I feel like I should know. I've written multiple SNMP MIBs and implemented those MIBs in an SNMP agent.
- Getting even simple data out of SNMP like "how full is my disk?" can differ between operating systems.
- Getting simple data out of SNMP like "how many messages has my SMTP server processed today?" can be downright awful if that simple bit of data isn't part of an existing, well-known MIB.
- And using multiple operating systems means dealing with multiple SNMP agents: OpenBSD has their snmpd(8), FreeBSD has bsnmpd, and pretty much everything else uses Net-SNMP. Each one has their specific nuances and features.
Code quality⌗
Do. Not. Get. Me. Started.
- The presentation and markup code is entangled with the application code. Reading the code is like trying to pull that CAT5 cable out of the drawer you shoved it in and having the RJ45 connector getting caught on everything and then you just give up and open a new package. Except you can't give up with Cacti. You're forced to look at the code because...
- There's very, very little error checking! Because apparently in Cacti land everything runs perfectly all the time. I've had to look under the hood at Cacti far more times than I'd care to admit in order to debug some sort of problem or errant behavior.
Customization is a necessity⌗
Due to the limitations around SNMP and getting all the data out that you want (eg, SMTP transactions), customization is almost mandatory when using Cacti.
Be prepared to deal with some or all of these in order to poll your custom data source: shell scripts, PHP scripts, XML files, data sources template, data queries, and graph templates.
It's fragile⌗
It feels like a house of cards.
- Cacti itself is just a bunch of PHP files so of course there's a dependency on PHP and then PHP needs a bunch of modules to do things like create images and those modules depend on shared libraries and of course don't forget the RRD tool set oh and MySQL and those modules oh and course there's font libraries too which you probably want so your graphs look nice and puuurdy.
- If any of those pieces are missing, or gets upgraded and doesn't quite work right with the rest, then it's back peeking under the hood to try and figure out what's going on.
The fragility was really the last straw. Every time I did an operating system upgrade and subsequently upgraded all of the third-party software on my Cacti machine, I would inevitably end up troubleshooting some aspect of the Cacti ecosystem.
And that is why I've switched to Zabbix. And with enthusiasm!
Introduction to Zabbix⌗
The Zabbix website bills Zabbix as "the ultimate enterprise-level software designed for real-time monitoring of millions of metrics collected from tens of thousands of servers, virtual machines and network devices." What I cannot convey to you, reader, from this quote is just how different the Zabbix website feels from Cacti's site. The Zabbix site has the polish and pop of a site run by... a company. Well, turns out, that's because it is. Zabbix is the product and Zabbix LLC is the company which leads development on the product and is in the business of selling support, training, and integration services to companies that use the product.
Now even though there is a commercial entity behind Zabbix, the product is:
- Open source (GPLv2)
- Developed in the open (publicly accessible bug/feature tracker and source code repository)
- Free to download and use
The product is multi-platform (OpenBSD, FreeBSD, Linux, Solaris/Illumos/OmniOS, macOS, Windows), looks amazing, and was very, very easy to get it to a point where I was trending data. I'm so impressed with how professional and polished this software is that I cannot believe it was a free download. It's just that good.
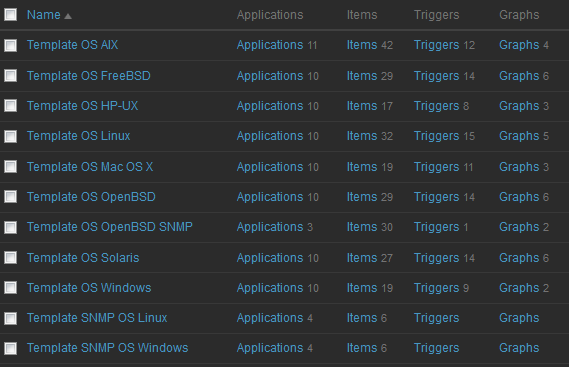
The Zabbix server UI makes heavy use of templates which greatly helps in getting everything to a useful state. The software also includes a feature called "discovery" where it can automatically detect things like number of CPUs, file systems/drives, and network interfaces in a server or network device and automatically create data sources (which in Zabbix nomenclature are called "items"), triggers, and associated graphs for each one. After just a few clicks, Zabbix will discover all the items, begin polling and set up the graphs and so on. No extra fussing around. Vey clean. Very simple.
Discovery can even go a step further and automatically discover hosts on the network and add them to the inventory (and subsequently create items, graphs, etc) but I haven't made use of that capability yet so cannot comment other than to mention that I know it exists.
Software Architecture⌗
Zabbixes architecture...err, Zabbix's architecture? Zabbixez? Aaaanyways, the architecture of this application has four basic building blocks:
- The server
- The web front end
- The agents
- The proxies
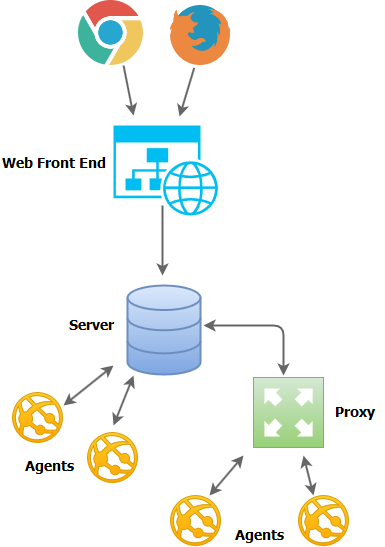
What Zabbix calls "the server" is actually a couple dozen processes that run on a "server" machine and takes care of tasks such as talking to the relational database, executing the polls by talking to the agents/proxies, and sending notifications due to events. The server is the controller of the Zabbix environment.
The web front end is a discrete piece of the architecture and can be colocated on the same machine as the server or put somewhere else such as a dedicated web server box. If you're thinking ahead, yes, this does strongly suggest that the Zabbix developers have thought about proper separation of presentation and application code! This separation of duties also supports a highly scalable deployment by allowing separation of duties onto their own, dedicated hardware and/or VM instance.
The agents are the bits of software that run on the devices that you want to monitor and relay telemetry back to the server for storage in the database. This is a key enabler of why Zabbix supports so many platforms. More on this in the next section.
Lastly, the proxy is just that, a proxy between the server and a bunch of devices that are to be monitored. The use case for a proxy is if the server sits in a different security zone than the devices to be monitored. It's easier to punch a hole between the two zones for the server and proxy to talk to each rather than for the server to talk to multiple different devices in the other zone. I also understand that a proxy can help scale the Zabbix installation by offloading data collection duties from the primary server, but I don't quite understand how well that scales since the primary server ends up having to handle all the data that the proxy collects anyways.
Regardless how the data gets to the server, once it's there it's all stored in a relational database (MySQL, PostgreSQL, Oracle, DB2, or SQLite); no RRDs or on-disk data storage. Aside from a very small .conf file on the file system, all of the configuration for the server is stored in the relational database along with all of the data that is collected from all of the hosts.
High Fidelity Data Without SNMP⌗
A key differentiator between Zabbix and NMSes that rely soley on SNMP for data collection is that Zabbix can actually put an agent directly on the host that's being monitored. This is a very powerful feature that enables capabilities that SNMP-based NMSes either don't have or cannot do easily.
First off, since the agent is the one that will be doing the actual data collection from the host (ie, fetching the current CPU load, or number of logged-in users), the agent is the piece of software that has to be platform-dependent. For example, the OpenBSD agent knows how to talk to the OS and find the CPU load. Same for the Windows agent, and the Solaris agent. This alleviates the Zabbix server processes from having to know all of these platform-specific mechanisms; the agent takes care of interrogating the platform using its built-in knowledge of the platform and simply communicates back to the server using a common protocol.
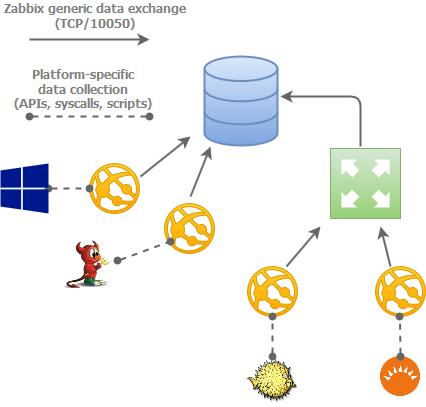
In this sort of architecture, the server software can stay very lean and relatively simple.
Another benefit this brings is that in order to extend the software to be able to gather additional or unique pieces of data that it's not able to gather out of the box, all of the customization for collecting that data is done at the agent level. The agent natively supports running third-party commands or scripts which can be used to gather additional bits of data. Once the data is collected and fed back into the agent by the script, it's sent back to the server over the existing communications channel using the common communications protocol; no jumping through hoops or any unnatural acts trying to figure out how to get the data off the host and into the database. This sort of thing is a very manual process with Cacti and involves some combination of SNMP MIBs, XML, and PHP scripts.
One thing that seems to be the norm with Zabbix is sub-five minute data collection intervals. I'm not certain if this is due to user demand or because their software can handle it. I have a feeling it's probably a mix of both.
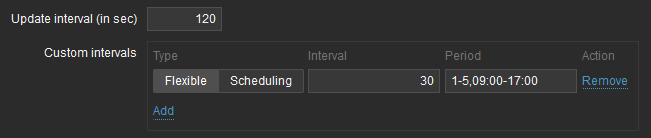
Cacti installs with a five minute default polling interval. There is support for going to sub-five minute but it involves multiple steps to configure and requires deleting the historical data for the data source(s) you want to poll more frequently. By contrast, a default install of Zabbix is setup to gather data for most items on a 60-second interval. These intervals are configurable on a per-item basis which allows a very high degree of control.
Another unique Zabbix feature is dynamic customization of the interval based on the current date and time. A common use case is to poll something more frequently during business hours (Mon-Fri, 0900 - 1700) and less frequently outside of that range. Again, this is configurable on a per-item basis.
Security Focused⌗
In my opinion, this is one of the key ways to measure the quality of a piece of software: how present and integrated are the security features. In the case of Zabbix, they do a few things out of the box that protect the integrity and privacy of the system and harden it against attack.
The communication between agent and server can be encrypted using public key infrastructure (PKI) (ie, certificates issued by a certificate authority) or pre-shared key (PSK). In either case, all communication between an agent and the server is secured ensuring that:
- The communications messages cannot be intercepted and read
- The communications messages cannot be intercepted and altered
- A rogue agent cannot attempt to impersonate the real agent
I can't speak for the Windows agent (haven't used it and don't plan to), but all of the Unix-like agents as well as the server give up their root permissions and live their lives as a non-privileged user. This is table stakes these days as far as security goes, but all the same, it demonstrates thoughtfulness and forethought to engineer the software such that it does not require root privileges to perform its duties. As you can see below, there isn't even a priveleged parent process; all process are running as the regular user _zabbix.
~% ps -axwo user,ruser,pid,command | grep -E 'zabbix|USER'
USER RUSER PID COMMAND
_zabbix _zabbix 52181 /usr/local/sbin/zabbix_agentd
_zabbix _zabbix 70772 zabbix_agentd: active checks #1 [idle 1 sec] (zabbix_agentd)
_zabbix _zabbix 88669 zabbix_agentd: listener #2 [waiting for connection] (zabbix_agentd)
_zabbix _zabbix 17331 zabbix_agentd: listener #1 [waiting for connection] (zabbix_agentd)
_zabbix _zabbix 3789 zabbix_agentd: collector [idle 1 sec] (zabbix_agentd)
_zabbix _zabbix 85931 zabbix_agentd: listener #3 [waiting for connection] (zabbix_agentd)
Community⌗
This is another strong measure of the quality of software: the strength of the community surrounding the software often parallels the strength of the software. Zabbix appears to have a very high quality and deep community.
- There are the (almost obligatory) online forums.
- There is really, really good documentation on all aspects and features of the software.
- There is the Zabbix Share site which is a platform for sharing templates that can be used to monitor different devices, applications, and systems which are all contributed by Zabbix users.
- There is a well used, high traffic bug and issue tracker and feature request tracker with active participation between Zabbix LLC and the wider community of users.
Besides these official resources, there are also plenty of blogs and articles across the web that talk about using Zabbix and offer instructions or help on upgrading or creating new templates.
One thing I've struggled to find is a web-accessible version of their source code repository. It appears they use SVN as their SCM of choice but their repo (svn://svn.zabbix.com) does not appear to have a web-based front end for browsing the repo, history, diffs, etc. Even looking to Github fails because what looks like the official git mirror of the SVN repo is empty.
Other than a web-based SVN interface, I've found the community to be great and it has been able to answer all my questions and more.
Wrapping Up⌗
Let me try and sum all of this up. How does Zabbix address the pain points I had with Cacti?
- No RRDs; all data is stored in a relational database.
- SNMP is an optional method for data collection; the primary method is using the native Zabbix agent which is multi-platform, provides dozens of different data items, supports highly granular data collection intervals, and is easily extendable.
- The code is high quality, with a clear separation between application logic and interface/UI code. The software architecture is well thought out and promotes scalability and clear separation of duties. There is a public bug and issue tracker where defects are discussed, reviewed, and resolved.
- Zabbix is highly functional out of the box thanks to sensible and wide-ranging templates for various operating systems and applications. The templating system makes customization rather easy and efficient, with many customizations being possible just by amending or adding to the existing OS/app templates.
- I don't have enough stick time with Zabbix to reasonably comment on its stability or resiliency, however based on a) my experience so far and b) everything else about Zabbix, I have little worry that the software will prove itself to be resilient across operating system and application upgrades.
Further Reading⌗
In case you're interesting in learning more about Zabbix, these are some of the links I referred back to regularly as I was getting my feet wet.