When a Port Channel Member Link Goes Down
Mohamed Anwar asked the following question on my post "4 Types of Port Channels and When They're Used".
"I need a clarification, where if a member link fails, what will happen to the traffic already sent over that link ? Is there any mechanism to notify the upper layer about the loss and ask it to resend ? How this link failure will be handled for data traffic and control traffic ?"
— Mohamed Anwar
I think his questions are really important because he hits on two really key aspects of a failure event: what happens in the data plane and what happens in the control plane.
A network designer needs to bear both of these aspects in mind as part of their design. Overlooking either aspect will almost always open the network up to additional risk.
I think it's well understood that port channels add resiliency in the data plane (I cover some of that in the previous article). What may not be well understood is that port channels also contribute to a stable control plane! I'll talk about that below. I'll also address Mohamed's question about what happens to traffic on the failed link.
Control Plane⌗
The control plane in a network is responsible for building neighbor/adjacency relationships between network elements, for learning network topology information, and for feeding information to the data plane so traffic can be properly forwarded through the network. A bouncy and unstable control plane has a direct effect on the data plane and therefore has a direct effect on the network's ability to forward traffic.
Put another way: a happy and stable control plane ultimately leads to a happier network.
Some examples of control plane (CP) protocols:
- Spanning Tree Protocol (STP) - CP for Layer 2 domain
- VLAN Trunking Protocol (VTP) - CP for advertising VLAN information in a Layer 2 domain
- OSPF/EIGRP/BGP - CP for a Layer 3 domain
- Protocol Independent Multicast (PIM) - CP for a multicast domain
- Label Distribution Protocol (LDP) - CP for an MPLS domain
Here's one more piece of background before I get to how port channels help the control plane: the four-step process that is followed when an event happens in the network that requires the network to reconverge:
- Detect that the event has happened
- Propagate the fact that the event happened to all neighbors
- Process locally that the event has happened and decide what to do about it
- Update the data plane so that it can continue to forward traffic based on the latest information that the control plane has
Let's examine this 4 step process with an example. Let's assume the event is a switch failure and we're looking at things from the point of view of a neighboring switch that's directly connected to this failed switch.
- Detect - The switch adjacent to the one that failed will be the first to detect the failure, possibly due to the network interfaces connecting to that switching losing signal and going down.
- Propagate - In order to give the network the best chance for fast convergence, a message is sent to other neighboring switches that this event has occurred so they can start their own 4 step process as soon as possible. In this example, this could be a Topology Change Notification (TCN) message sent via STP.
- Process - The switch that's running this process will now execute its own convergence algorithm and determine what needs to happen in order to keep traffic moving in the network in light of this failure. In this example, it could be STP choosing a new root port or designated port.
- Update - Lastly, the control plane has to instruct the data plane about the new decision(s) it has made so that traffic can continue to flow in the network. In this case that could be flushing the MAC address table.
It's worth noting that step 4 — programming the hardware — can sometimes be the step that takes the most time. TCAM memory — which is used to hold the forwarding tables in many switch and router platforms — is really, really fast when it comes to read operations but is quite slow when software needs to write new information into that memory.
Ok, now let's look at a similar example but with a port channel thrown in.
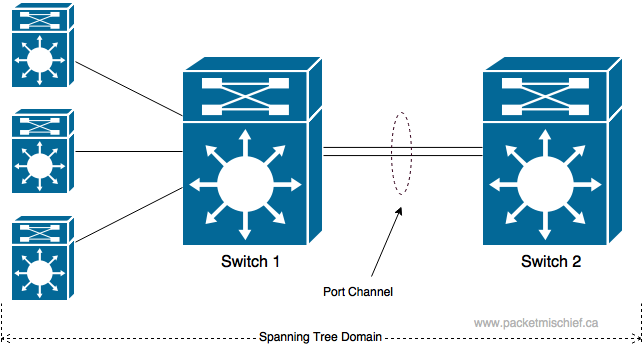
Switch 1 is the switch we'll examine and Switch 2 is its neighbor. Instead of a full switch failure, this time we'll look at a failure of a single link (and come back to a switch failure later). The two switches are now connected via a 2-member port channel.
- Detect - One of the links goes down which causes Switch 1 to detect loss of signal on that interface.
- Propagate - This is where things get interesting. If we think about the topology now from the point of view of the control plane — Spanning Tree — then has anything changed? If there's still an active member of the port channel and the port channel interface remains up, then the Layer 2 topology has not actually changed and the control plane doesn't need to execute steps 2, 3, and 4.
While STP doesn't need to reprogram the data plane, the data plane still needs to realize that a link has failed and that it can't use that interface any longer. I'll cover this in "Where Do the Packets Go?" below.
By using a port channel in this network, the impact of a link failure was isolated to the two switches that are connected on that link. The rest of the network had no idea that a failure occurred and there was no reconvergence necessary from a control plane perspective on any of the switches.
Here's another example, this time with a Layer 3 switches and routed port channels (the port channel interfaces have IP addresses assigned to them).
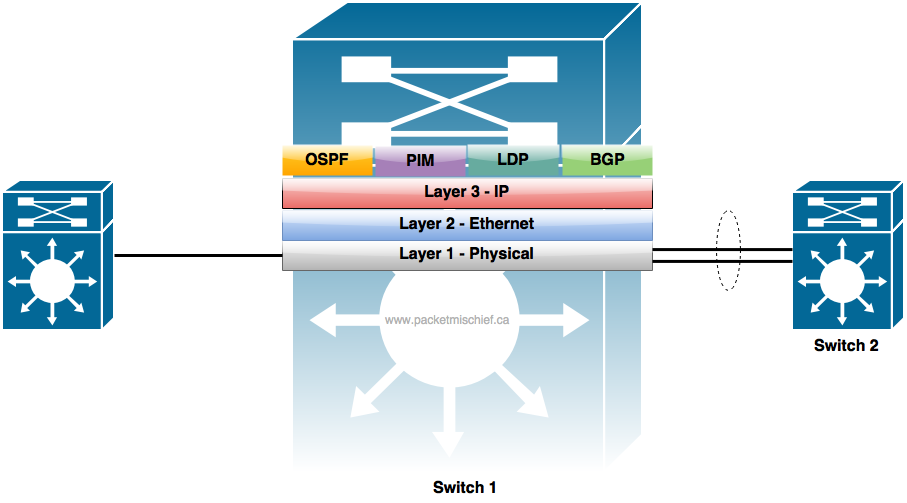
If one of the member links fails between Switch 1 and Switch 2:
- Detect - Link goes down.
- Propagate - We know from the previous example with Layer 2 switches that the Layer 2 connectivity between Switch 1 and 2 isn't affected. And for the same reasons, the Layer 3 topology isn't affected either. Switch 1 and 2 still have IP reachability over the port channel.
So just like in the Layer 2 example, the Layer 3 control plane protocols don't have to reconverge either because the topology of the network didn't actually change.
I just told a little white lie. EIGRP might actually reconverge (depending on a number of circumstances) when the link goes down because the bandwidth of the port-channel interface will change and EIGRP might decide it needs to update all neighbors on this change in metrics. OSPF might also reconverge depending on the previous and new bandwidth values of the port channel and the reference bandwidth setting on the switch. Both protocols can be explicitly tuned so that they don't reconverge in this circumstance.
To summarize: one of the biggest benefits of using port channels is that a failure of a link is an isolated event and does not cause a ripple affect through the network. This keeps the control plane steady which is good for the stability of the network.
Control Plane - Next Level⌗
Let's go further with the idea of control plane stability. I described in the previous section how a port channel will offer protection when a member link fails. What about if the adjacent switch fails (like the example I used when I explained the 4 step convergence process)?
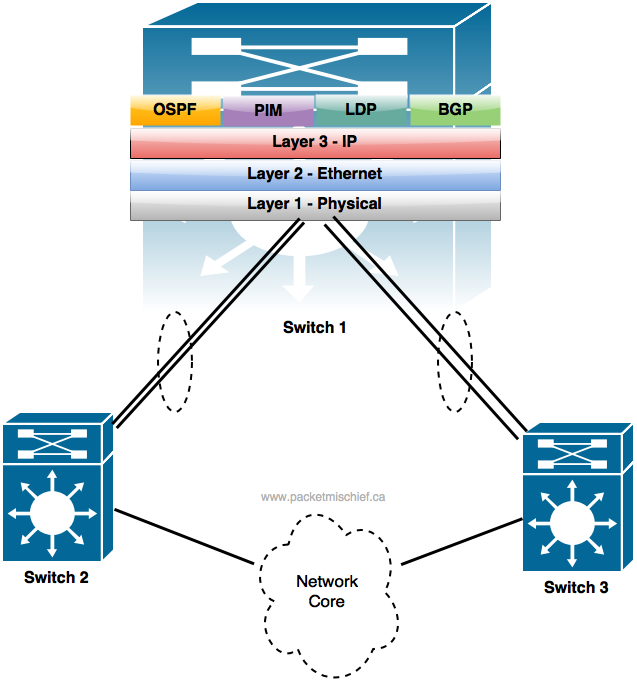
In this topology, let's assume we're still working with Layer 3 port channels and that Switch 2 fails completely. Is there a network topology change?
The answer is yes, because that entire link between Switch 1 and Switch 2 is now gone so the Layer 3 control plane protocols must converge.
A way to engineer around this is to add an additional technology that allows for a more resilient port channel configuration. That technology is called (generically) multi-chassis link aggregation (MLAG). Different vendors have different names for their technology that enables MLAG. Cisco has StackWise, Virtual Switching System (VSS) and Virtual Port Channel (vPC). Juniper has Virtual Chassis (VC). Regardless of its name, MLAG allows for the member ports to terminate on two different network elements while still belonging to the same port channel.
For example, if Switch 2 and Switch 3 were configured to support MLAG, the two individual port channels could be reconfigured into one, 4-member port channel.
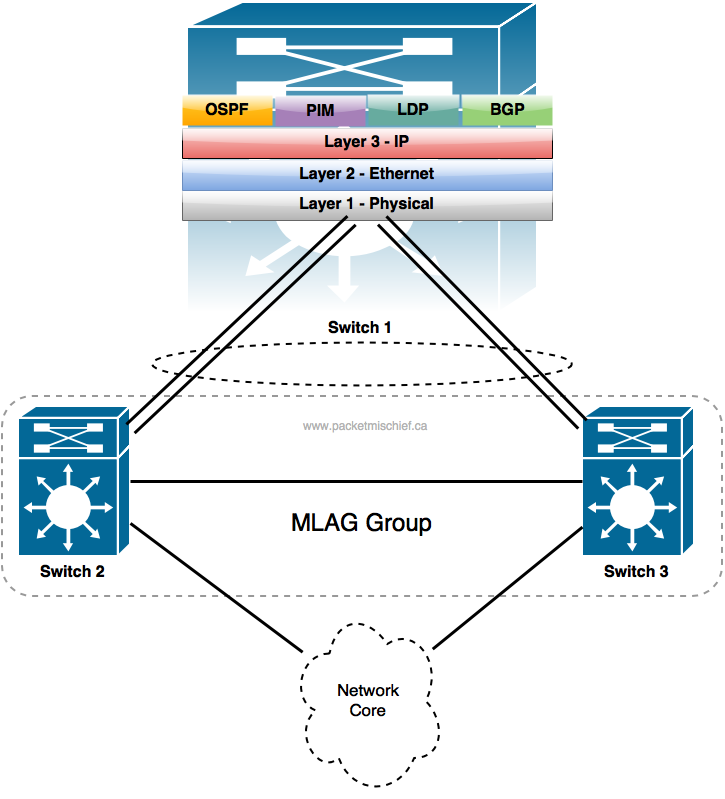
What the MLAG configuration does is basically trick Switch 1 into thinking that all 4 physical links are connected to the same neighbor switch and that it can safely bring up the port channel. Switch 2 and Switch 3 perform some magic to ensure there's no logical loop between Switches 1, 2, and 3 (note there is a physical loop) and that's more or less it. Now if one of the member links fail, or Switch 2 or Switch 3 have a serious failure and both of their member links go down, the Layer 3 topology remains the same and the control plane is once again not involved in any reconvergence.
This is one of the biggest benefits of VSS/vPC/VC technology. They enable a much more resilient network design thanks to enabling multi-chassis port channels which in turn — as stated above — isolates a link, or in this case an entire chassis failure, to just the two switches where the failure occurred. The rest of the network remains unaware and unaffected.
Where Do the Packets Go?⌗
Mohamed also asked what happens to packets on the link when the link fails and is there a mechanism to retransmit any data that was lost.
The short answer is that the packet(s) on the wire when the link fails are lost. The switches themselves do nothing to recover the lost data. It's up to upper layer protocols to handle any retransmits. For example, TCP will notice missing packets and take care of retransmissions. Sometimes the application itself will notice and (hopefully) take care to ask the sender to retransmit.
It's actually not quite as simple as this though. There could be packets sitting in the tx-ring for that interface. They are also lost. Also remember the 4-step convergence process: programming the data plane is the last step. And until that step is completed, traffic is black-holed.
When it comes to port channels, updating the data plane typically involves updating some sort of table that maps a hash result or an index to a physical port. The exact implementation of the table and the mapping is highly dependent on the hardware platform and since this post is already quite long, I'm just going to leave it at that.
The amount of time it takes to update this table is finite and measurable. It's not instantaneous. In some of the lab testing I've done with Cisco gear, I've seen anywhere from < 50ms to 2000ms depending on the platform, specific failure scenario and traffic type. Keep this in mind when you're planning your next maintenance window: while your control plane may not reconverge, there is a hit in the data plane. It will likely be a brief hit, but if you have really sensitive applications, they might notice.
Disclaimer: The opinions and information expressed in this blog article are my own and not necessarily those of Cisco Systems.