The Anatomy of a Cisco Spark Bot

I spent a long time creating my first Spark bot, Zpark. The first commit was in August and the first release was posted in January. So, six months elapsed time. It's also over-engineered. I mean, all it does is post messages back and forth between a back-end system and some Spark spaces and I ended up with something so complex that I had to draw a damn block diagram in the user guide to give people a fighting chance at comprehending how it works.
Its internals could've been much simpler. But that was part of the point of creating the bot: examining the proper architecture for a scalable application, learning about new technologies for building my own API, learning about message brokers, pulling my hair out over git's eccentricities and ultimately, having enough material to write this blog post.
In this post I'm going to break down the different functional components of Zpark, discuss what each does, and why-or not-that component is necessary. If I can achieve one goal, it will be to retire to a tropical island ASAP. If I can achieve a second goal, it will be to give aspiring bot creaters (like yourself, presumably) a strong mental model of a Spark bot to aid their development.
Update: I've updated the hyperlinks in this post to point to webex.com instead of ciscospark.com.
Let's X-Ray Zpark⌗
If we looked at the guts of Zpark, the innards would organize into groups that look like this:
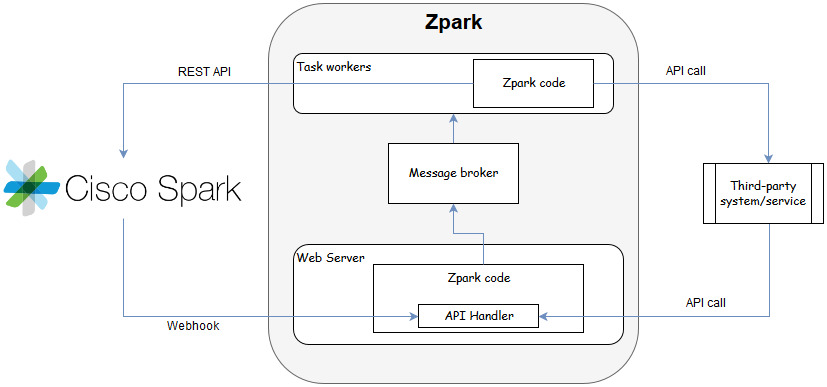
Each block in this diagram represents specific functionality in the bot and together, make up the fully functioning automaton. The sections that follow will review each major block; one of them is required and two of them are overdoing it (unless you're building something highly scalable or are a gluten for taking on extra work, like yours truly). I will call out which is which as we go. One thing I won't be doing is mentioning specific technologies. If you want to build your bot using the latest async-node-module-with-css-mixins-on-a-blockchain-and-hashtag-enabled-artificial-intelligence, you go right ahead. You'll still need to follow a model like the one I'm going to describe.
Before tucking in though, let's crystallize our mental model for how Spark bots function.
Let's go Model Building⌗
Building models can be fun (Unless you have to paint them, too. What is this, art class?). Building mental models is how we begin to understand things that we don't yet know much about. And we usually build a new mental model by basing it on something that we do already understand.
When I first learned that Cisco Spark (a collaboration platform with heavy emphasis on text-based chat) supported the concept of a bot (a client that connects to the service and responds autonomously to simple commands), I built a mental model based on something that every geek kid who grew up with the Internet in the 90s knew about: Internet Relay Chat (IRC) and the Eggdrop bot.
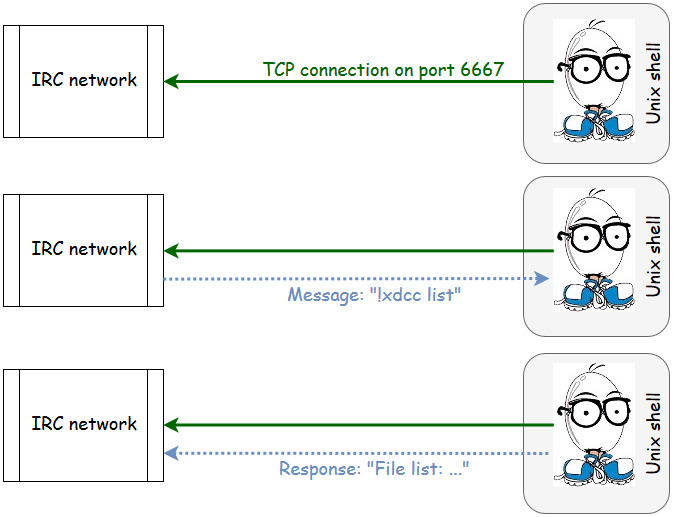
Pretty simple, right? The bot is basically a client that opens a connection to IRC and sits there, watching events happen, and responding when it sees something it's been programmed to respond to. The bot software itself runs as a background process on a server somewhere (or a hacked shell, lulz).
You can now forget that you ever saw this.
Spark doesn't work anything like this. And that's one of the reasons this blog post exists: because if you're like me, you (very reasonably) formed a mental model much closer to Eggdrop than to the reality that is Spark.
With that, let's examine how a Spark bot is put together.
Web Service⌗
The web service is the one functional block that's required. Ok, that's a lie, it's not really. Well, it is required if you want to send commands to the bot. But if you don't, it's not. If your bot just sends messages to Spark and doesn't process events that happen on Spark, then not only do you not need a web service but you probably don't need to keep reading. You're basically making a client that just consumes the Spark API at that point. Go read the API docs and be done.
This is where the biggest delta is between the Eggdrop model and the Spark model: a Spark bot does not act as a traditional client of the service and does not receive event notifications over a long-running communications session to the service.
A Spark bot needs to implement a web service that, at a minimum, listens for webhook callbacks. A webhook callback is how the Spark service will notify the bot of an event (eg: someone joining a room, a new message, or someone adding the bot to the room). The implementation of a webhook callback is really simple: it's an HTTP POST with a JSON payload to a URL that your bot is listening on. Your bot simply listens for such an HTTP request, decodes the payload, and takes some action based on the data in the payload.
Webhooks are used instead of long-lived sockets like Eggdrop uses because a) it's, like, very Web 2.0, b) it's crazy scalable, and c) on a global scale, it just makes logical sense given that any web platform worth its salt has an API, the API is likely REST-based, and an endoint can easily be built into the existing REST API framework to handle a webhook callback.
Now, the implementation of your web service will differ somewhat depending on what technologies you're using to build your bot, but you'd likely have a proper web server fronting all of the requests with your application logic running logically "behind" this server.
Another element that you may need to put in your web service is a block chain. Haha, just kidding, couldn't resist. It's actually an API. If your bot needs to receive events from a third-party system (like Zpark does), then you need to expose some way for that third-party system to interact with the bot. And all the cool bots have APIs, so you'd better give your little bot one too unless you want it to be sad. And as I wrote above, your webhook receiver is quite likely to be heavily intertwined in the API framework, so you're already taking the first few steps towards API-ness anyways by building a webhook receiver.
Now that your bot has the ability to receive events from Spark via webhook callbacks, it needs to take action. There are really two approaches:
- Synchronous handling: The same operating system (OS) process that receives the webhook callback does the event processing, runs the application logic, performs third-party communications, and takes the necessary action(s).
- Asynchronous handling: The OS process that receives the webhook callback does only the minimal amount of work necessary and then passes the event information on to a worker process.
Synchronous handling is much easier to code and has less dependencies. Asynchronous handling is more complex. So naturally, we're going to look at the async model. This isn't without benefit though: the async model results in a more scalable bot, capable of handling many more events at a time. I also get to keep using the term async in this article, which I suppose benefits me more than you. C'est la vie.
But first, in order to really maximize the sizzle of the async architecture, let's look at boring old synchronous first.
The Synchronous Model⌗
In the synchronous model, everything happens in order, one after the other. The OS process that's working on a task has to fully complete the task before it can move to the next one. And it can only work on one at a time. Just like me doing chores around the house.
Let's get fancy and visualize what this looks like in the context of a bot receiving a webhook callback from Spark:
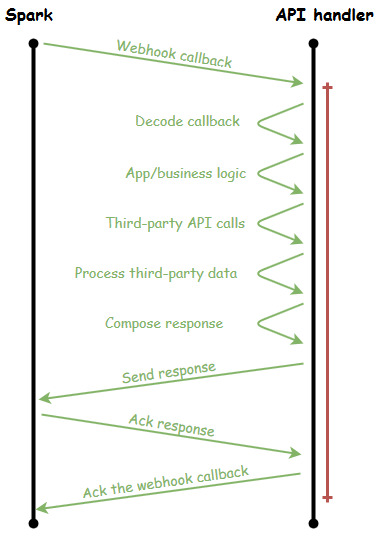
Within the same OS process, the webhook is handled but so is all the logic and communication required to deal with the webhook request. Note the vertical red line on the right: this line represents how much of the timeline the API handler was tied up dealing with this one request. For my color-blind friends, it's, like, all of the time. And how many other requests can this API handler service while it's in this red zone of the timeline? Exactly zero. And that's a shame because a lot of the time consumed in the red zone is actually spent waiting on I/O to complete (don't count on third-party API calls to be snappy, and that includes the calls to Spark) and could instead be put to work servicing other requests.
And now you understand why the synchronous model has scale limits: the API handler is blocked from handling any other requests while it's in the red zone. What the API handler needs is a helper that it can order around to do the grunt work while it goes about its business of just handling API requests.
Workers⌗
The workers are the OS processes that are spun up in order to handle the heavy lifting of a task. They sit around drinking coffee and playing cards until the boss comes around and yells at one of them to go do something. That "something" is the logic and communication required to deal with the webhook request. If we update the timeline to show a task worker, we see that all of the heavy, more time-consuming tasks have been delegated to a worker:
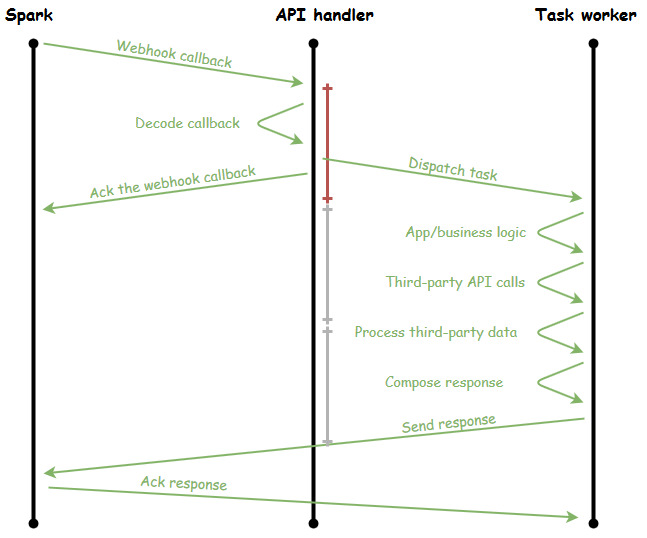
Notice the size of the red vertical line now: it's shrunk a great deal because the API handler does minimal work itself (slacker!!). In fact, it's handling the incoming webhook callback so quickly, that it could handle more than 3 callbacks in the time it takes the task worker to finish the task (and those are totally made-up numbers since the length of the red line was totally arbitrary, however the point stands that the API handler can do more in less time now).
Buuuut, the question should now be: if the API handler can work so much faster than a task worker, isn't there a bottleneck? What happens when there are no free workers and the API handler tries to lob a task over its shoulder to one of them?
Well, truth is, the API handler and the task worker don't actually talk directly with each other; they go through a broker.
Message Broker⌗
The message broker is the trusted third-party that reliably delivers messages from the API handlers to the task workers. It's much like that kid in class who passes notes between people except the message broker doesn't suck and get caught by the teacher causing YOU to get in trouble (thanks a lot, STEVE).
What were we talking about?
Oh, the message broker also has smarts in it. Things like only delivering messages to a recipient at a specific time of day; fan-out of messages to multiple recipients; message queues with quality of service, and of course a bevvy of plugins, tools, and integrations.
If we keep building out our timeline, the broker would fit in like so:
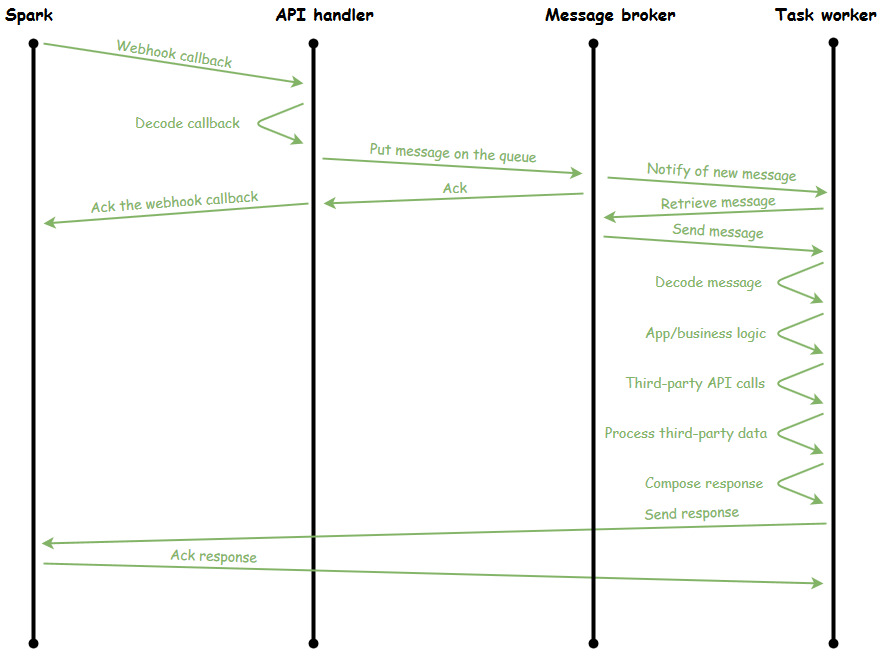
The message that the API handler sends through the broker would include the name of the task that the worker should run, the data that the worker will need to complete the task (like what was inside the payload of the webhook callback), and any special delivery instructions the broker needs in order to deliver the message.
The main worker process, upon being notified of a new message by the broker, pulls the message off the queue and dispatches the message to one of the workers in the worker pool (Yes, the workers have organized into a hierarchy. They also have their own book club). That worker then opens up the message and runs the task that's named in the message.
While the workers are, erm, working, the API handlers continue to place tasks in the message broker queue. When a worker frees up, they're assigned the next task in the queue. Workers can take whatever time they need in order to finish the task without impacting the receipt of API and/or webhook requests on the front end.
Screw Async: I'll Just Run Dozens of API Handler Processes⌗
No, you won't.
My, that was rude of me.
Ok, you could, but there are side effects. The resources needed to handle a task are probably more demanding than what's needed to just handle an API/webhook request. More memory and more CPU. While you could run dozens of heavy-weight processes that do everything with their larger memory footprints and CPU demands, that's not really... optimal.
Further, if you end up in a situation where you need to scale out your infrastructure because your bot just got Slashdotted (is that still a thing? or is my 90s showing again?), how do you scale out a monolithic design like that? If you decouple the API handler from the worker, you can naturally scale the layer of the bot that needs it: move the workers to different servers, scale the number of worker servers, and so on.
Do I Really Need Async?⌗
No, you don't.
There, that felt less rude for some reason.
Use the tools that make sense for whatever it is that you're building. Are you building a bot for an enterprise with tens of thousands of potential users? You better be thinking about scale and speed. Are you working on a personal project to post custom memes in your space? Then maybe you don't care. Do you just want to learn more about building scalable software? Niiice! Jump right in.
Re-reading this post (which I do about 47 times before ever hitting the publish button), I realize it got a bit derailed in comparing the sync vs async models. That wasn't meant to be the point. However, understanding those two models and choosing one over the other fundamentally changes the anatomy of the bot so I think it was electrons well spent.
Happy botting. If you are interested in building a Spark bot, please comment below. You can also find me in the #spark4dev Spark space (I only just now realized there is a literal hash in that space name; a little IRC throw-back perhaps? Aaaand now we've come full circle so I can stop typing).
Exit.