How I Relearned the Consequences of Improper Monitoring
I had just lost the RAID array that hosts my ESXi data store. I didn't yet know that's what had happened, but with some investigation, some embarrassment, and a bit of swearing, I would find out that an oversight on my part three years ago would lead to this happening.
I first realized there was trouble when every VM on the host became unresponsive. Most notably, the Plex Media Server fell off the network which caused the episode of Modern Family that we were watching to immediately freeze. What was odd to me is that while the VMs were unreachable, the ESXi host itself was fine. I could ping it, ssh to it and load it up with the vSphere client. The first wave of panic hit me when I found messages like this in the host's event log:
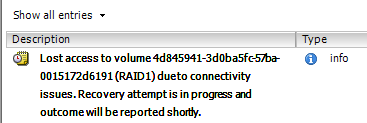
This was quickly confirmed from the ssh shell by looking for the data store and finding that a) the symlink for the volume (RAID1) pointed to a non-existent directory and b) the reported size of the volume was a paltry 450MB compared to the 930GB I expected.
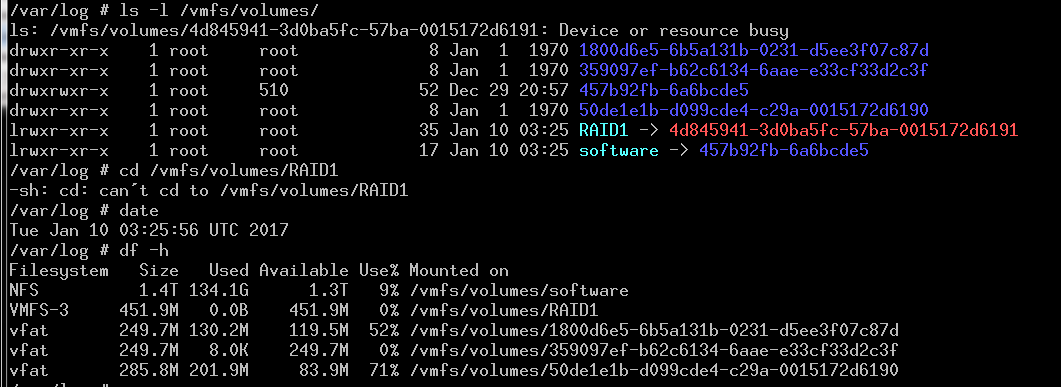
Since I knew from prior experience that ESXi has no capabilities to manage LSI RAID volumes, I chose to reboot the host and jump into the MegaRAID BIOS. That's when the second wave of panic hit: the BIOS was showing that both drives in the RAID group were faulted. This seemed highly bizarre to me. I've seen my share of drive failures but I had never had two go at the same time. In search of more information, I started looking through the event log in the BIOS (which, by the way, is painful when you don't have a mouse connected to your KVM) and since all good things come in threes, that's when the third wave of panic hit:
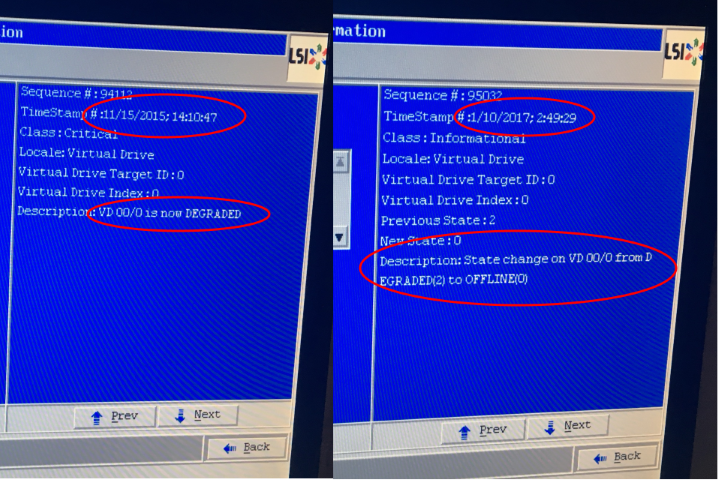
Both drives were indeed offline and as a result, the virtual drive-the RAID volume itself-was gone. What I couldn't understand was how the hell I was unaware of the drive failure from all the way back in Nov of 2015. 2015!
Finding the Fault⌗
Thankfully, the drive that had most recently faulted was not toast. I was able to manually mark it as "good" and boot back up with the array in a degraded state. Now that things were back online, I could finish my investigation (and of course it also gave me some breathing room to procure new drives!).
Step 1 - I referred back to a prior blog post-Monitoring Direct Attached Storage Under ESXi-to verify where I should be looking to see the health of the storage within the vSphere client. Only problem was, my client wasn't showing the same information as my old screen shots; there was absolutely no status being shown for the direct attached storage.
Step 2 - Verify that the proper VIB is installed for monitoring my hardware, in this case, an LSI MegaRAID family card.
~ # esxcli software vib list | grep -i lsi
~ #
Oh shit.
As soon as I saw that output I knew what had happened.
Three Christmases ago, I used the extra time off work to upgrade ESXi on this machine. I boot ESXi off a USB thumb drive and instead of doing an in place upgrade (is that even a thing?) I just got a second drive, installed new, and imported the saved config (at least, that's what I remember doing). What I didn't do was install the third-party VIB from LSI for the RAID card. So from that point onward, I had no monitoring capabilities on the storage. In 2015, the first drive failed with nary a peep. And then just the other day, the second drive had a serious enough hiccup that the array fell over completely.
How to Avoid #Failure and Get Your Monitoring Right⌗
Here's what I did to turn monitoring back on (and what I should've done after booting the new version of ESXi three years ago).
Step 1 - Download the VIB from the vendor. Because of a whole bunch of M&A, LSI is now owned by Broadcom. I'm not going to provide a direct link to the download page since vendor URLs are prone to change. Navigate to the section of the site for the LSI RAID cards, find the downloads area and look for the VMware "SMIS" provider download. The file I downloaded was named VMW-ESX-5-x-0-lsiprovider-500-04-V0-54-0004-2395881.zip so look for something similar (and mind the version of ESXi you're downloading for).
Step 2 - Get the .vib file onto the host. Open up the .zip file you downloaded and copy the .vib file to the host. I find a quick scp to be the easiest. If you haven't enabled SSH on your host, there are dozens of articles out there on how to do that.
Step 3 - Install the VIB with the esxcli command from the SSH shell:
~ # esxcli software vib install -v vmware-esx-provider-lsiprovider.vib --no-sig-check
[VibDownloadError]
('vmware-esx-provider-lsiprovider.vib', '', "[Errno 4] IOError: <urlopen error [Errno 2] No such file or directory: '/var/log/vmware/vmware-esx-provider-lsiprovider.vib'>")
url = vmware-esx-provider-lsiprovider.vib
Please refer to the log file for more details.
Welllll, that didn't work. Turns out the command demands the fully qualified path to the .vib file (at least on this version of ESXi) even if the file is in your cwd.
~ # esxcli software vib install -v /vmware-esx-provider-lsiprovider.vib --no-sig-check
Installation Result
Message: The update completed successfully, but the system needs to be rebooted for the changes to be effective.
Reboot Required: true
VIBs Installed: LSI_bootbank_lsiprovider_500.04.V0.54-0004
VIBs Removed:
VIBs Skipped:
Much better. Also note the use of --no-sig-check. Since this is a third-party package this argument is necessary.
A quick reboot of the host and everything is installed and loaded.
~ # esxcli software vib list | grep -i lsi
lsiprovider 500.04.V0.54-0004 LSI VMwareAccepted 2017-01-11
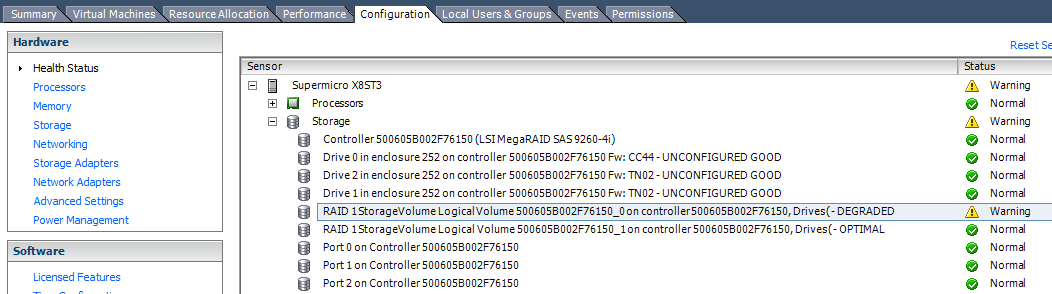
Verify that everything is working by looking in the vSphere client for the details and health status of the attached storage:
The Value of Doing a Dry Run⌗
One of the things that helped me quickly identify what was going on and resolve the situation was the fact that I had done a dry run of a disk failure prior to the system going live. More importantly, I had carefully documented the results. This proved very valuable for a few reasons:
- Even though I didn't initially know how the RAID group had gotten into a failed state, I had a baseline which was telling me that something had changed somewhere along the line; I used to be able to see health status of the storage but I couldn't any longer.
- It gave me a path to follow during my moments of panic. I knew the steps to follow to inspect the health of the RAID group in the BIOS and I knew the steps to take to initiate a repair of the array.
- Lastly, it gave me a known-good state that I could use to check the system against once I rectified the drive failures and fixed the issue with monitoring the storage. I now know that everything is running just like it was when I first did that dry run.
How to Really Fail at Logging⌗
This isn't really material to the overall story, but I learned a little something that I'm sure will be useful in the future so it's worth mentioning.
I wanted the log files that ESXi generates to be stored on persistent storage so they're available after a reload of the host. Since the only persistent storage in the host is the RAID drive, I configured that as the location for the log files.
That's a great idea until the RAID drive goes offline, all the VMs go unresponsive and you have no idea what's going on. When I attempted to check the logs for more information they were of course unavailable. Doh.
When I was standing at the console of the host, I started cycling through all of the virtual consoles with Ctrl+Alt+Fx and found that F12 actually shows a real time tail of the vmkernel log. Perfect!
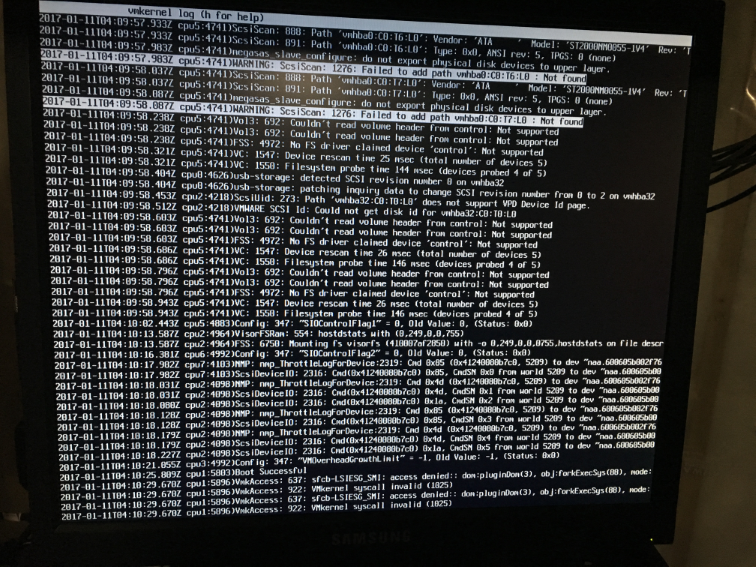
I imagine this would've been very useful as a second step in troubleshooting, after realizing that the on-disk logs were unavailable.
Conclusion⌗
I think I can sum this all up very succinctly:
- The results of not taking due care that your monitoring tools/methods/processes are working could be a disaster.
- After a software upgrade, re-check your baseline against actuals. Look for things that are outside the norm and for things that aren't there that used to be.
- Resilient systems can often mask the fact that a fault has occurred. See above: make sure your monitoring is dialed in!
I'm very fond of a quote I saw many years ago which, near as I can tell, is attributed to Peter Drucker, who, also near as I can tell, had little-to-nothing to do with IT :-). He said,
What gets measured, gets managed
I think this quote is very well suited to the IT world. Measurement and monitoring of IT systems is critical in order to effectively manage them.